In the first two parts of this blog, we presented the Fischertechnik factory simulation. This factory simulation should now continuously generate data that should end up in a big data cluster on the one hand and be reportable using SAP BW or SAP Analytics for Cloud on the other.
We set up a Cloudera installation as a big data cluster. Similar to Linux, the free open-source operating system that can be purchased in preconfigured and then paid versions (e.g. Suse Linux, RedHat,…), there are also preconfigured installations of Apache Hadoop, e.g. from Hortonworks or Cloudera. We opted for Cloudera and installed a 60-day free Enterprise Edition. As this is only a demo application, it has also become a simple cluster with just one node.
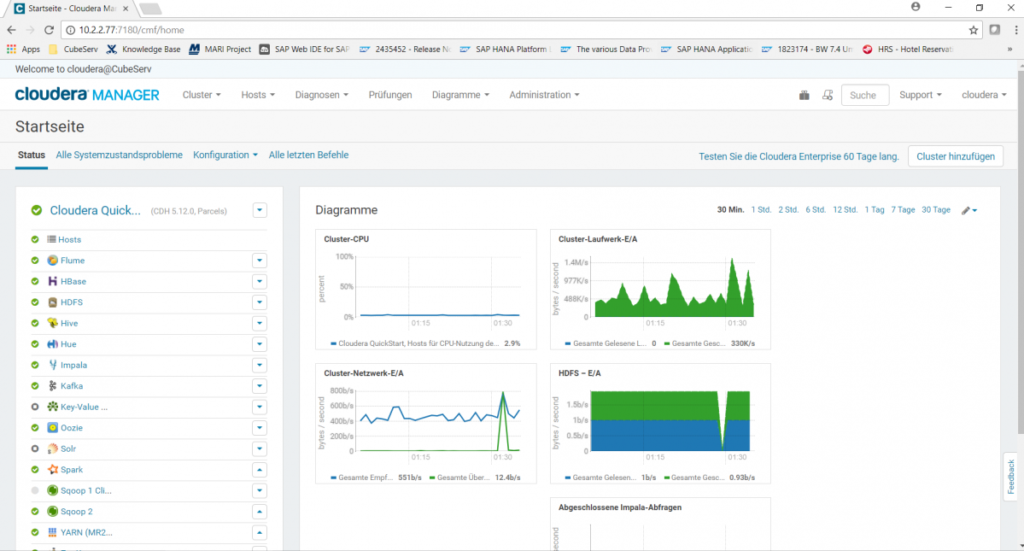
Hadoop comes with a whole range of services that initially mean little to the layperson and are initially very confusing in terms of their number and meaning.
- HBase is the system’s database.
- HDFS is the Hadoop Distributed File System, which stores data redundantly and thus guarantees high reliability.
- Hive is a service that allows SQL-like queries against the system’s database.
- Impala enables faster SQL queries than Hive thanks to better parallel algorithms. Impala is primarily used for fast reading and less for other operations such as creating, writing, or changing.
- Hue is a service that offers an SQL query workbench and visualization. Here you can try out SELECT statements, for example (and choose whether you want to query via the Hive or Impala engine).
- Kafka allows you to load and export data streams.
- Oozie is the service used to schedule batch jobs.
- YARN is the resource management service that also controls the allocation of queries to servers.
- Flume is a service for streaming logs to Hadoop.
The Fischertechnik factory is controlled via the Siemens Logo control units. The control units and their programming interface now offer the option of writing the states of all existing inputs and outputs at periodic intervals (e.g. 1s) to a log file such as Log.csv. All inputs and outputs are always written, but we have initially limited ourselves to just three, namely the controls for the sorting chutes that separate white, red, and blue plastic cylinders from each other, depending on the color detected in the photocell.
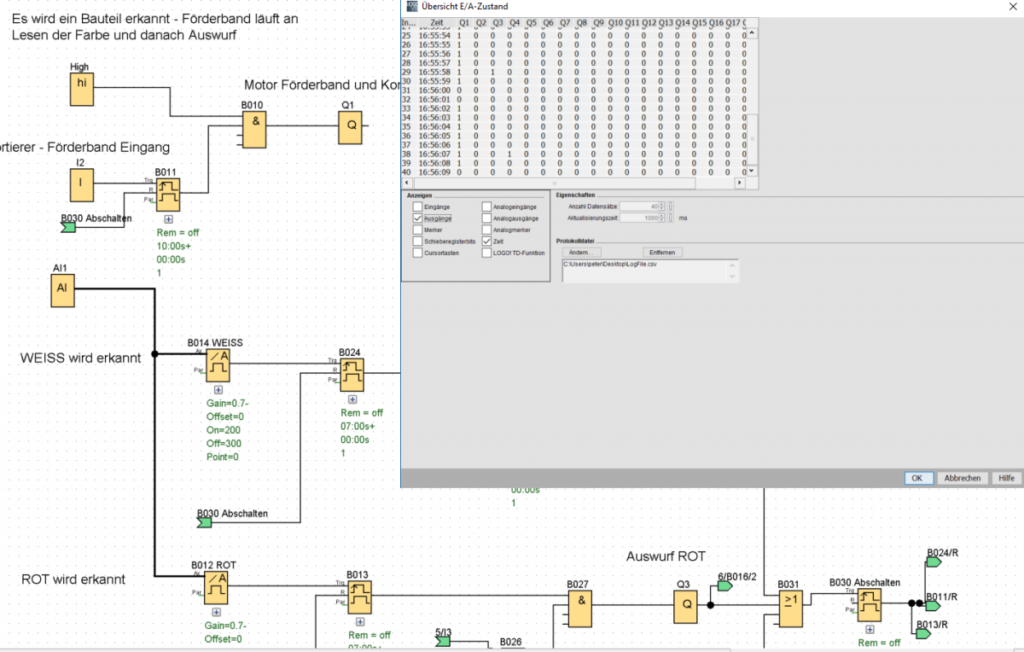
This created the simplest possible report, namely a simple counter that counted how often a 1 was reported by motor Q2 (white), Q3 (red), or Q4 (blue). This then corresponded to the corresponding number of plastic goods passed through.
The Siemens control interface is therefore constantly writing to a local CSV file on the laptop, which is used to control the small system. This is therefore the source of our sensor data. The directory in which this log file is written has now been mounted on the Cloudera system via Samba. This meant that a CSV file was available locally from the point of view of the Cloudera system. At the same time, there was no risk that a brief interruption of the connection would lead to the writing process being aborted. Writing continued permanently and if the connection via the Internet was interrupted, the new data could be retrieved the next time the connection was re-established.
This locally visible CSV file, the LogFile.csv, is now permanently written to a target in Kafka with the help of a Flume agent. The corresponding configuration instruction, which defines a source, a destination (sink), and a channel, is as follows:
#------------------------------------
tier1.sources = r1
tier1.sinks = k1
tier1.channels = c1
# Describe/configure the source
tier1.sources.r1.type = TAILDIR
tier1.sources.r1.filegroups = f1
tier1.sources.r1.filegroups.f1 = /samba/FischerTechnik/LOG/LogFile.csv
tier1.sources.r1.positionFile = /tmp/flume-position_3.json
# Describe the sink
tier1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
tier1.sinks.k1.topic = sensor_csv
tier1.sinks.k1.brokerList = quickstart.cloudera:9092
tier1.sinks.k1.batchSize = 1
# Use a channel which buffers events in memory
tier1.channels.c1.type = memory
tier1.channels.c1.capacity = 100000
tier1.channels.c1.transactionCapacity = 10000
# Bind the source and sink to the channel
tier1.sources.r1.channels = c1
tier1.sinks.k1.channel = c1
#------------------------------------
For setting up this configuration, many thanks once again to the experts at our partner company for Hadoop systems, Ultra Tendency GmbH (www.ultratendency.com), and especially to Matthias Baumann, who has already helped us several times with his Hadoop expertise.
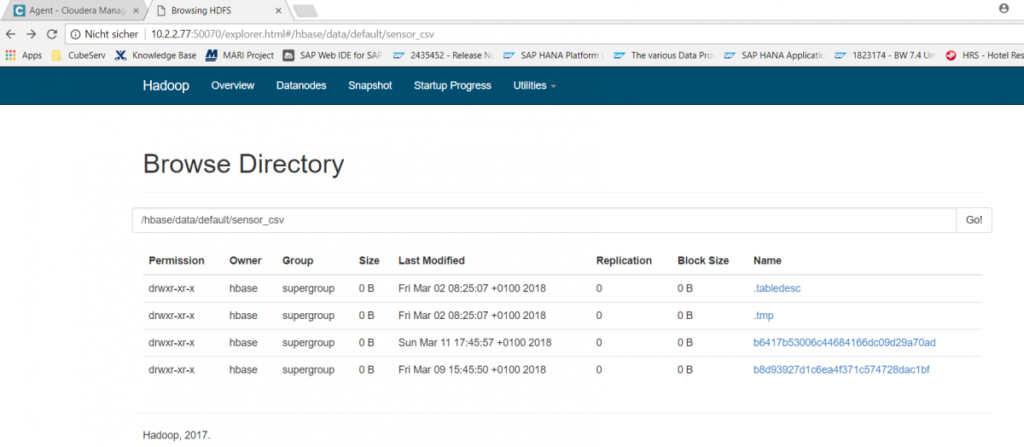
The sensor_csv file is now available in Cloudera in the HDFS file system and receives new data every second. To make this CSV file available for SQL queries, the following command is issued in Hive:
CREATE EXTERNAL TABLE sapt90.zcssensorq (
key varchar(6),
time VARCHAR(8),
value VARCHAR(4),
sensor VARCHAR(20)
)
STORED BY "org.apache.hadoop.hive.hbase.HBaseStorageHandler"
WITH SERDEPROPERTIES (
"hbase.columns.mapping" =
":key,default:time,default:value,default:sensor"
)
TBLPROPERTIES("hbase.table.name" = "sensor_csv")
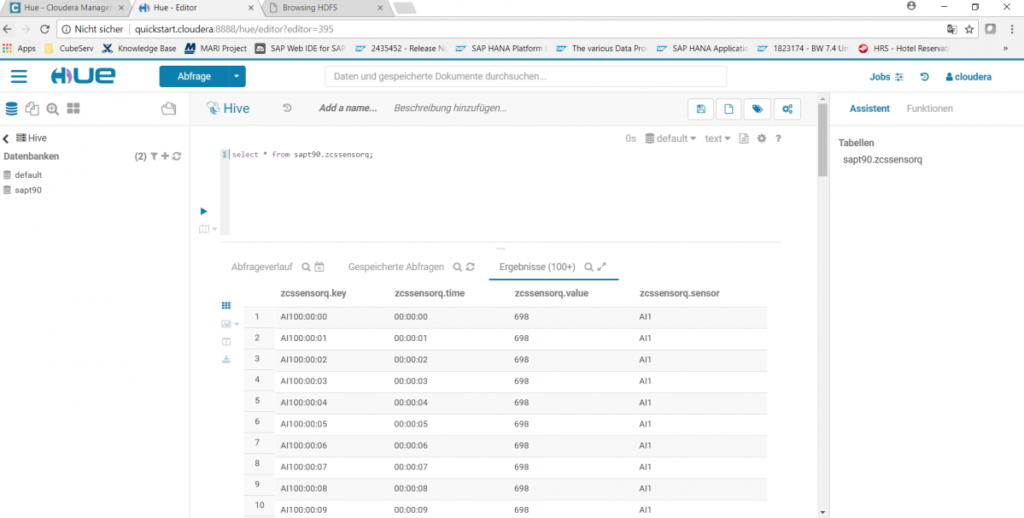
This command creates an empty table shell zcssensorq (in a schema with the name sapt90) with 4 columns (key, time, value, sensor) and informs the system that the content of this table is located in an HBase table with the name sensor_csv. In this way, simple Hive or Impala queries can now be started in the Hue service, e.g. select * from zcssensorq;:
The sensor data from the Fischertechnik factory is thus written continuously and is available as a file or table in the Hadoop system. How can this data now be made available for reporting? This is the subject of the next part of this blog.
