In the previous part, data from ECUs were written to a CSV file, this was imported into Hadoop via Kafka and read via Hive adapters or Impala adapters in a HANA database. These adapters provide a convenient way to access the Hadoop data in read-only mode.
However, these adapters do not allow write access to the tables. If, for example, you want to move data that is no longer particularly important but still should not be deleted (“cold data”) to Hadoop, you cannot do this via these adapters.
A simple way to move data back and forth between an ABAP system and Hadoop is offered by the middleware GLUE, which is developed and distributed by our partner company Datavard. It offers the possibility to define tables in Hadoop from ABAP (these are then called GLUE tables) in a way similar to what is done in SE11. The contents of these tables can be displayed as easily as with SE16, and writing to these tables is also very simple. The GLUE software requires an application server on Linux, but no HANA database is mandatory, the software also works on classic databases.
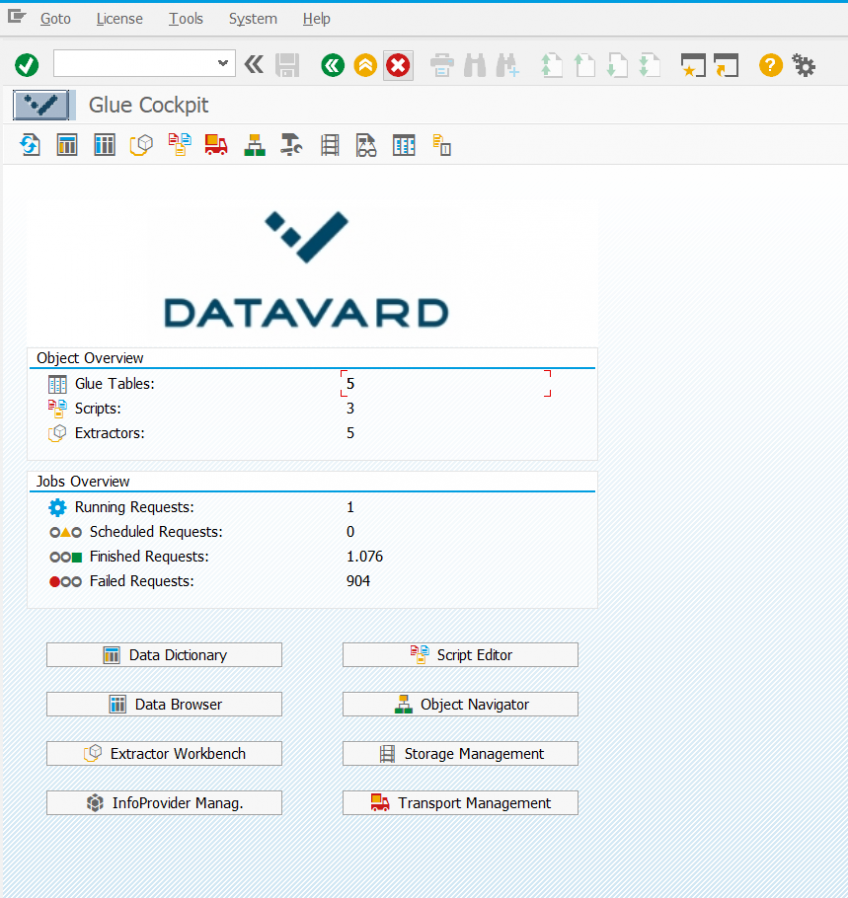
An example: after successful import via ABAP transport requests and after appropriate configuration, the transaction /DVD/GLUE is available as a central entry point:
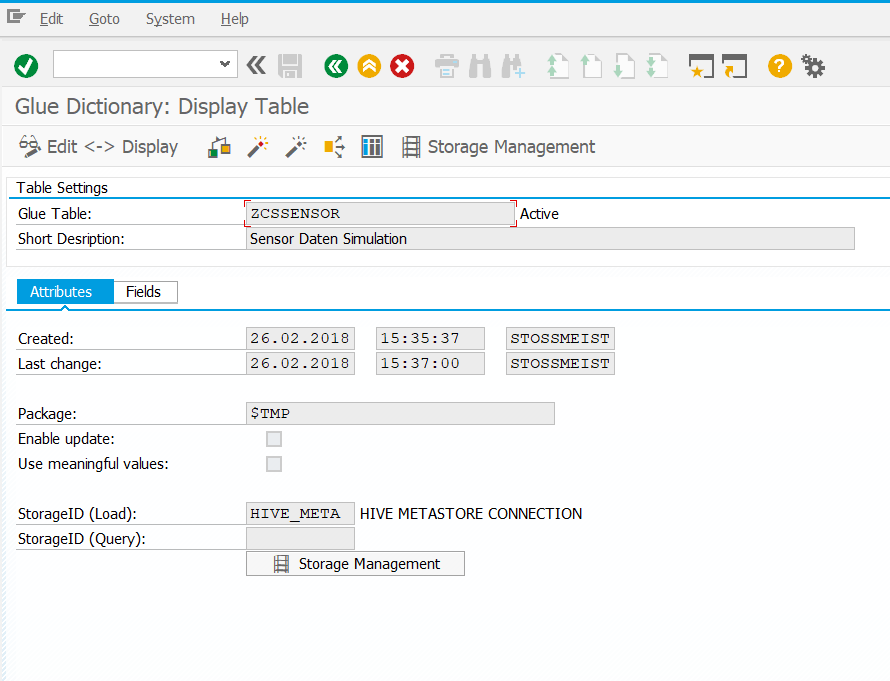
For example, a table ZCSSENSOR can be defined in the Data Dictionary:
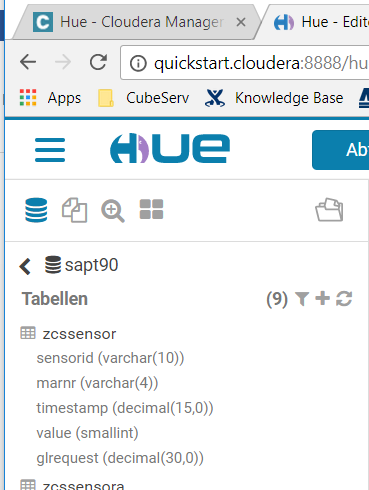
After activation, this table can then be found in Hadoop:
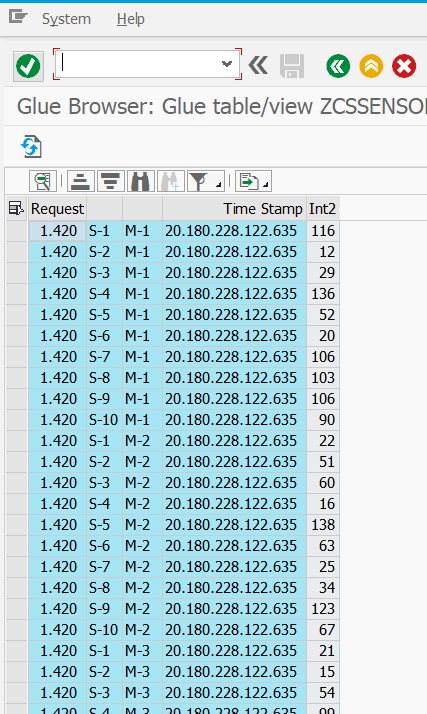
The contents of this table can be displayed in ABAP just as easily:
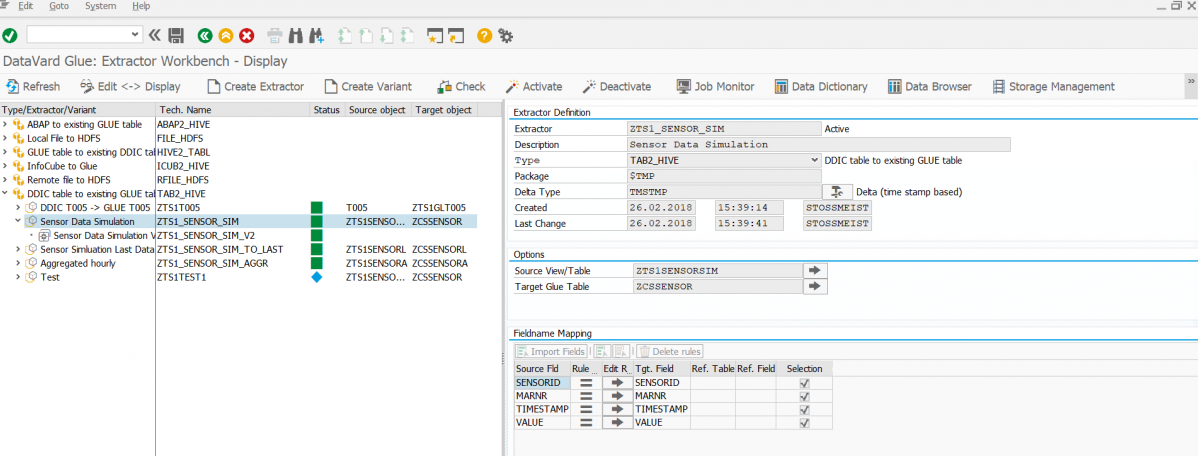
Now, how was this data that you see here brought into this table? In /DVD/GLUE you can find the extractor workbench. Here you can define a kind of transformation e.g. between an ABAP table from the DDIC and a GLUE table:
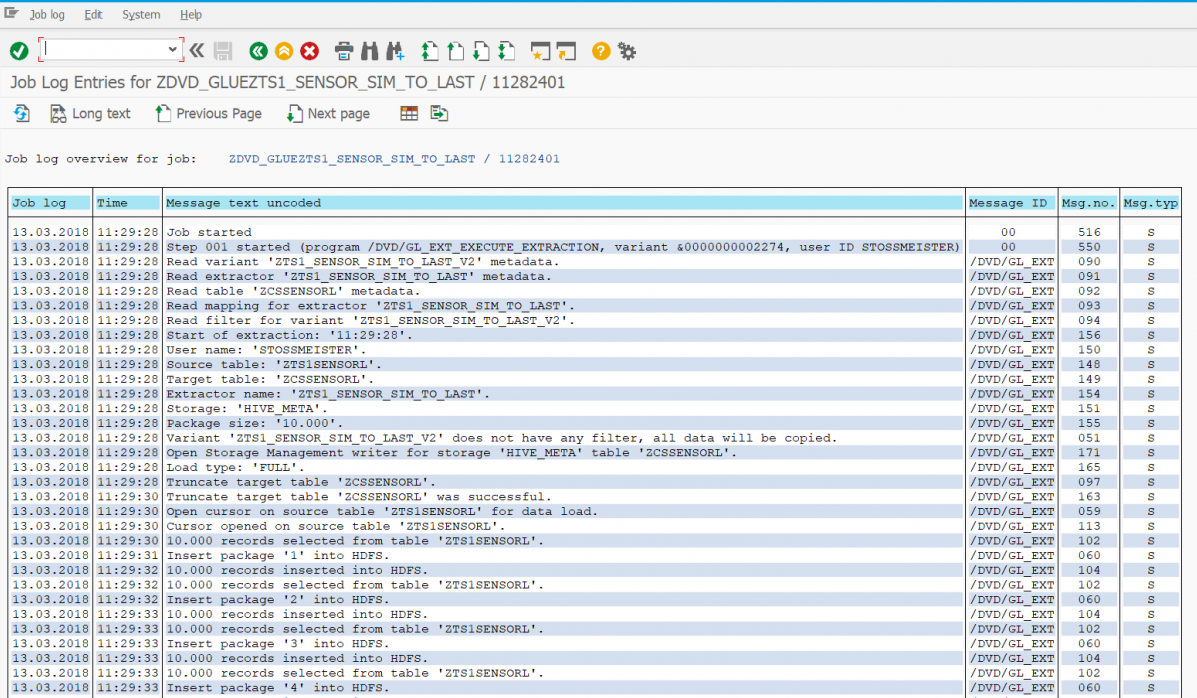
In addition to this extractor (it roughly corresponds to a transformation), a variant is defined (it roughly corresponds to a DTP). This variant can then be scheduled as a job and then performs the data transfer. After execution, one can see in the corresponding job log how the transfer was performed (here using the zcssensorl table as an example):
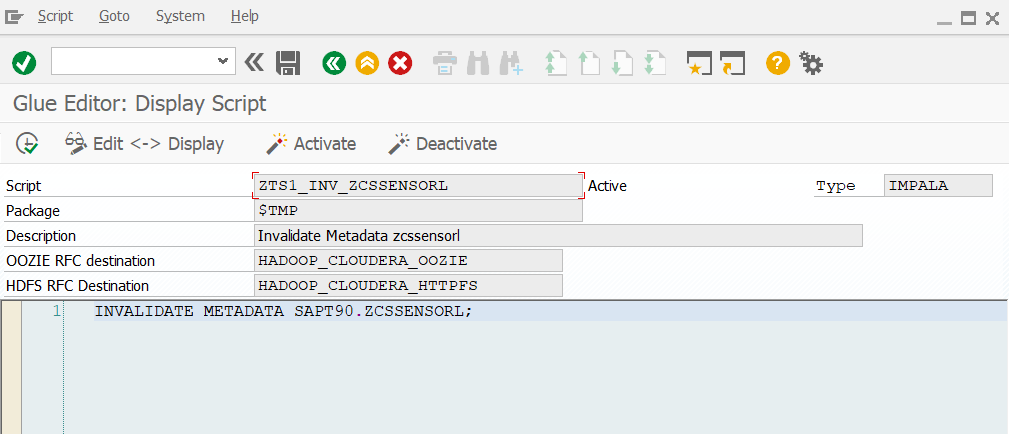
As mentioned earlier in the blog, you generally need not only an exchange of data but also an orchestration of events. GLUE offers the control centrally from the ABAP. With the help of the Script Editor, commands to the Hadoop can be defined in ABAP, e.g.
And these commands are then also started from the ABAP:
Overall, GLUE offers a convenient way to address and use Hadoop from ABAP. This opens up the Hadoop world to the user without having to delve deeply into the details of this technology.
Subscribe our Newsletter
Keep up to date on SAP Analytics Cloud, SAP Data Hub, and Big Data, and do not miss any news, downloads & events.