Wie erheben Sie das volle Potential Ihrer Daten? Die Vernetzung der verschiedenen Akteure ist der vielversprechendste Weg, um mit schnellem, agilem Arbeiten hochwertige Ergebnisse zu erreichen. So werden Berichtsempfänger zu Gestaltern mit Fakten. Data Mesh weist den Weg zu einer Zusammenarbeit auf Augenhöhe. Sie haben noch nichts zum Data Mesh-Konzept gehört? Gerne stelle ich es Ihnen kurz vor.
Sie kennen die Situation bestimmt auch: Es ist Mittwoch und zahlreiche Hiobsbotschaften trafen in den letzten Tagen ein: Aufträge mussten storniert werden, die nächste Corona-Welle baut sich auf und die Entwicklung im Winter ist aufgrund der unsicheren Energieversorgung mehr als unklar. Die meisten Daten werden Sie im Data Warehouse finden. Nur ist es nicht so einfach, die verschiedenen Abfragen „richtig“ zu interpretieren und in neue Analysen einfliessen zu lassen.
Um hier schnell die richtigen Entscheidungen vorzubereiten, benötigen Sie qualitativ hochwertige Datenprodukte als Input und die Fähigkeit, selbst Daten zu kombinieren, aufzubereiten und zu analysieren. Abhängig von den Fragestellungen und Ihren Vorkenntnissen wird sich das von den Kollegen unterscheiden.

Heutzutage sind Daten allgegenwärtig und werden bei vielen digitalen Aktionen eingesammelt. Laut Statista lag das Gesamtdatenvolumen der Daten im Jahr 2020 bei 64,2 Zettabyte, und es wird prognostiziert, dass es bis 2025 auf 181 Zettabyte pro Jahr ansteigen wird (hbs). In dieser Atmosphäre ist eines klar: Daten sind das neue Öl der digitalen Wirtschaft. Und eine robuste Datenanalyse ermöglicht es Unternehmen, einzigartige Muster aus komplexen Datensätzen zu erkennen, die sie bei der schnellen und optimalen Entscheidungsfindung in einem immer dynamischeren Markt und in der Wirtschaft unterstützen.
Glücklicherweise bietet die Data-Mesh-Architektur einen Ausweg aus dieser Situation. Data Mesh wurde erstmals von Zhamak Dehghani, die zur Zeit der ersten Veröffentlichung bei Thoughtworks arbeitete, entwickelt. Es nutzt die Prinzipien des modernen Software-Engineerings und die Erkenntnisse aus dem Aufbau von robusten, internetbasierten Lösungen, um das wahre Potenzial von Unternehmensdaten zu erschliessen. Dieses architektonische Paradigma erobert nun die Branche im Sturm.
Veraltete Datenplattformen und ihre Unzulänglichkeiten
Bislang haben Unternehmen in der Regel auf Data Warehouses und Data Lakes zurückgegriffen, um grosse Datenmengen für Analysezwecke zu speichern. Daher hat sich die analytische Datenebene üblicherweise zwischen diesen beiden Hauptarchitekturen und -technologien aufgeteilt. Data Warehouses dienen als Repository für strukturierte, gefilterte Daten und unterstützen anschliessend die Zugriffsmuster für analytische und Business-Intelligence-Berichte. Data Lakes hingegen nehmen riesige Rohdatenpools auf, so dass Data Science ins Spiel kommen kann. Beide Plattformen waren jeweils in zentraler Verantwortung. So dass jede Veränderung durch einen aufwändigen Change-Prozess genehmigt werden musste und bis zur Produktivsetzung erhebliche Zeit ins Land ging.
Seit Jahrzehnten sind diese Plattformen das vorherrschende Paradigma für die Datenverwaltung. Diese Art von Dateninfrastruktur erzeugt zentralisierte und standardisierte Betriebsdaten, die dann an den Eigentümer der Domäne zurückgegeben werden. Diese Art von Datenarchitektur zielt darauf ab, Daten aus allen Bereichen des Unternehmens und von externen Datenanbietern zu konsolidieren und diese Rohdaten in bereinigte, gut organisierte, aggregierte Daten umzuwandeln, die für Berichte, Analysen, die Erstellung von Funktionen und die Modellierung verwendet werden können.
Obwohl im Laufe der Jahre erfolgreich bereichsorientiertes Design mit eingeschränktem Kontext in den operativen Systemen erstellt wurde, haben sich Datenplattformen vom bereichsorientierten Dateneigentum hin zu einem zentralisierten, bereichsunabhängigen Dateneigentum entwickelt.
Während dieses zentralisierte Modell für Unternehmen mit einfacheren Domänen und einer geringen Anzahl von unterschiedlichen Analysefällen ausreicht, stossen Organisationen mit umfangreichen Domänen, einer grossen Anzahl von Quellen und einer Vielzahl von Verbrauchern an die Grenzen eines zentralisierten Ansatzes:
- Auch wenn Unternehmen bisher auf eine zentralisierte Strategie für die Verarbeitung komplexer Datensätze aus verschiedenen Quellen zurückgegriffen haben, erfordert diese Methode, dass die Benutzer Daten von Edge-Standorten in einen zentralen Data Lake importieren, um sie für Analysen abzufragen, was zeitaufwändig und teuer ist.
- Da das globale Datenvolumen weiterhin exponentiell ansteigt, kann die Abfragemethode in der zentralen Verwaltung nicht in ausreichendem Masse reagieren, was zu einer Verlangsamung der Geschäftsabläufe führt. Letztlich wird die Agilität der Unternehmen beeinträchtigt, da sich die Reaktionszeit verlangsamt.
- Die Datenübertragung unterliegt häufig verschiedenen Datenschutzrichtlinien. Sie verbieten nicht nur die Datenmigration, sondern schreiben auch vor, dass die Daten an einem bestimmten Ort gespeichert werden müssen. So kann beispielsweise die Datenübertragung umständlich sein, wenn die Daten in einem EU-Land gespeichert sind und ein Nutzer in Japan darauf zugreifen muss. Auch hier wird die Flexibilität im Geschäftsbetrieb beeinträchtigt, da die Einhaltung von Data-Governance-Vorschriften und die Suche nach rechtlichen Schlupflöchern und Genehmigungen für den Datentransfer mühsam, teuer und zeitaufwändig ist.
- Die Unternehmen von heute müssen eine Vielzahl komplexer Entscheidungen treffen, denen die in den 1990er Jahren entwickelte Datenarchitektur einfach nicht mehr gewachsen ist. Insbesondere bei Data-Warehouses beobachten wir eine abnehmende Unternehmensflexibilität. Diese Datenverwaltungstools sind sehr kostenintensiv, da sie einen hohen Verwaltungsaufwand erfordern.

Automatisierten Berichten und Zusammenfassungen mangelt es oft an wirklichen Einblicken und Details. Die mangelnde Flexibilität der Infrastruktur bedeutet, dass es in der Regel eine erhebliche Verzögerung zwischen den Bedarf an Antworten und neuen Berichten gibt. Selbst wenn Details verfügbar sind, liegen die Daten möglicherweise nicht in einem Format vor, das eine besser lesbare Analyse im Zeitverlauf ermöglicht. Kurzum, Data Warehouses sind für neue ad hoc Fragestellungen nicht geeignet.
Was zeichnet die Data Mesh-Architektur aus?
Die dargestellten Herausforderungen machen eine neue Denkweise erforderlich, und hier kommt das Datengeflecht (Data Mesh) ins Spiel.
Data Mesh trägt der Allgegenwärtigkeit von Daten im Unternehmen Rechnung, indem es ein bereichsorientiertes, selbstverwaltendes Design einsetzt. Ziel ist es, Daten innerhalb eines Unternehmens leicht verfügbar und miteinander zu verbinden. Auch wenn die Idee etwas abstrakt erscheinen mag, ist eine grossartige Analogie für Data Mesh unser Nervensystem: Es besteht aus dem Gehirn und einem Netz miteinander verbundener unabhängiger Produkte (Organe).
Schauen wir uns die vier Prinzipien von Data Mesh an, um zu verstehen, wie sie funktionieren:
1. Domäneneigentum
Daten werden je nach Geschäftsfeld aufgeteilt, zu den Geschäftsbereichen, die den Daten am nächsten sind – entweder die Quelle der Daten oder ihre Hauptverbraucher. Zerlegen Sie die (analytischen) Daten logisch und auf der Grundlage der Geschäftsdomäne, die sie repräsentieren, und verwalten Sie den Lebenszyklus der domänenorientierten Daten unabhängig.
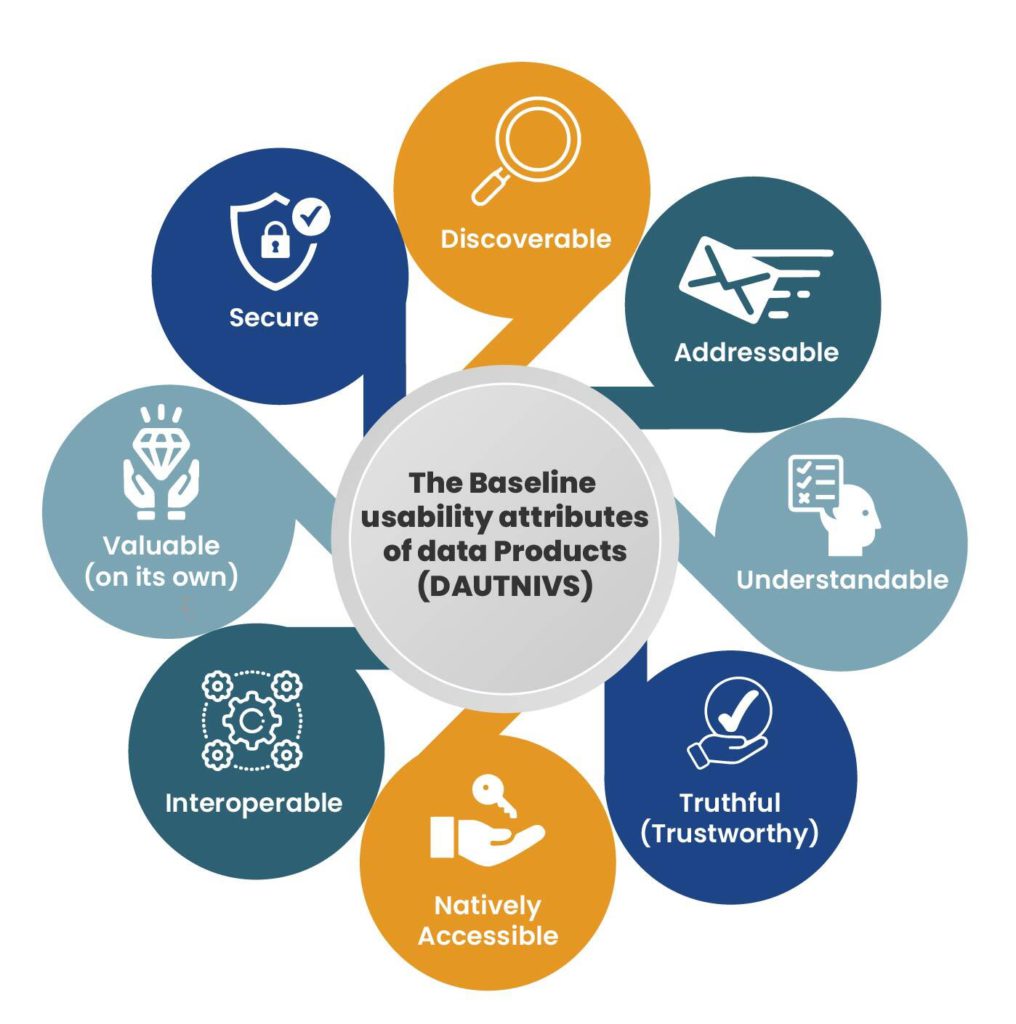
2. Daten als Produkt
Daten werden als ein Produkt betrachtet, das dem Team gehört, das sie veröffentlicht. Data Mesh verpflichtet die Fachteams, die Verantwortung für ihre Daten zu übernehmen. Das Team ist Eigentümer dieser Daten und muss die Qualität, Kohärenz und Darstellung seiner Daten sicherstellen. Erst durch die Anwendung der Datenprodukte zeigt sich, ob der Entwicklungsprozess erfolgreich gewesen ist. Datenprodukte sollen nicht den Entwicklern genügen, sondern sich durch die Anwendung rechtfertigen. Dieses Prinzip projiziert eine Philosophie des Produktdenkens auf analytische Daten.
3. Self-Service-Datenplattform
Daten sind praktisch überall im Unternehmen in einem Datennetz verfügbar. Nehmen wir zum Beispiel an, Sie möchten eine Absatzprognose für ein bestimmtes Produkt auf einem japanischen Markt erstellen. In diesem Fall sollten idealerweise alle Daten, die Sie für einen aussagekräftigen Bericht benötigen, innerhalb weniger Minuten verfügbar sein. Sie möchten nicht warten, bis ihre Anforderung priorisiert, eingeplant und umgesetzt ist.

4. Föderale Data-Governance
Das Hauptziel dieses Prinzips besteht darin, ein Datenökosystem zu schaffen, das die organisatorischen Regeln und Branchenvorschriften einhält und gleichzeitig die Interoperabilität aller Datenprodukte gewährleistet. In dem Zusammenspiel der verschiedenen Prinzipien wird deutlich, dass in einem leistungsfähigen Framework, dass weitestgehend automatisiert sicherstellt, dass die hohen Anforderungen umgesetzt sind, eine grosse Herausforderung liegt. Themen wie Datenschutz, Data Lineage, einheitliche Schnittstellen müssen vor der Einführung bedacht und getestet werden. Durch die dezentrale Verantwortung und Entwicklung der verschiedenen Datenprodukte besteht die Gefahr, dass Datensilos bzw. nicht mehr auflösbare Abhängigkeiten zwischen den einzelnen Produkten entstehen.
Warum sollten Unternehmen eine Data-Mesh-Architektur einführen? Die Antwort liegt ganz einfach in der Tatsache, dass diese Art der Datenorganisation am besten für moderne Geschäftsanforderungen geeignet ist und viele der Herausforderungen meistert.
- Das dezentralisierte Dateneigentumsmodell verkürzt die Zeit bis zu den ersten Erkenntnissen und die Zeit bis zur Wertschöpfung, indem es den Geschäftseinheiten und operativen Teams ermöglicht, schnell und einfach auf „Nicht-Kerndaten“ zuzugreifen und diese zu analysieren. Mit anderen Worten: Die Unternehmen werden flexibler und agiler.
- Die Datenverflechtungsarchitektur hilft Unternehmen, Entscheidungen in Echtzeit zu treffen, indem sie die zeitliche und räumliche Leerstelle zwischen einem Ereignis und seiner Analyseverarbeitung minimiert. Das Geschäftsmodell wird wesentlich effizienter und reagiert schneller auf sich ändernde Trends.
- Data Mesh überwindet zudem die Unzulänglichkeiten von Data Warehouses und Data Lakes, indem es den Dateneigentümern mehr Autonomie und Flexibilität und mehr Datenexperimente ermöglicht. Ausserdem verringert es die Belastung der Datenteams, die die Anforderungen aller Datenkonsumenten über eine einzige Pipeline erfüllen müssen.
Durchführbarkeit – Schlüssel zum Erfolg
Soll diese neue revolutionäre Datenorganisation eingeführt werden oder nicht? Um festzustellen, ob sich eine Investition in eine Data-Mesh-Architektur lohnt, müssen Unternehmen die Anzahl der Datenquellen, die Grösse der Datenteams, die Anzahl der Datendomänen und die Data Governance berücksichtigen. Im Allgemeinen gilt: Je umfangreicher und komplexer diese Faktoren sind, desto anspruchsvoller sind die Anforderungen an die Dateninfrastruktur Ihres Unternehmens und desto wahrscheinlicher ist es, dass Ihr Unternehmen von einem Data-Mesh-Ansatz profitiert.
In der Regel ist der Umstieg auf eine Data-Mesh-Architektur eine sinnvolle Überlegung für Teams, die grosse Mengen an Datenquellen und deren Verarbeitung zu sauberen Daten bewältigen müssen. Wenn die Datenanforderungen Ihres Unternehmens jedoch wenig komplex und anspruchsvoll sind, sollten Sie Data Mesh eher noch nicht in Betracht ziehen. Für Unternehmen, die sich schnell entwickeln und sich an die Datenmodernisierung anpassen wollen, ist es sinnvoller, zunächst einige Best Practices und Konzepte der Datenvernetzung zu übernehmen, um eine Migration zu einem späteren Zeitpunkt zu erleichtern.
Dieser Blog ist Teil einer Serie von Beiträgen zur Business Analytics. Ich empfehle eine Business -Analytics-Platform aufzubauen. Ziel ist es, den Anwendern eine Plattform für Ihre Bedürfnisse zu bieten, wo sie alle Daten und Analytics-Tool finden.
Bisher veröffentlicht:
- Teil 1: Wie Business Analytics erfolgreich gestalten?
- Teil 2: Business Analytics vs. Business Intelligence
- Teil 3: Was ist SAP Analytics? Das SAP Data Warehouse-Portfolio
- Teil 4: SAP Analytics – Die Front End Produkte
- Teil 5: Data Plattform – Ein wichtiger Pfeiler der digitalen Transformation
- Teil 6: Auf dem Weg in die AWS
- Teil 7: Cloud – Fluch oder Segen?
- Teil 8: Mit Daten führen – warum Power BI häufig zur Auswahl steht
- Teil 9: Business Analytics Plattform: Agilität und Data Governance
- Teil 10: Advanced Analytics mit SAP und R
- Teil 11: Mit SAP PowerDesigner datenmodellgestützt entwickeln
- Teil 12: IBCS konforme Charts mit Tableau und graphomate
- Teil 13: Schnell neue Insights gewinnen: Ist jetzt der richtige Zeitpunkt, um mit der SAP Data Warehouse Cloud zu starten?
- Teil 14: Erste Schritte mit R
- Teil 15: Advanced Analytics mit R: Eine Übersicht
- Teil 16: Data Culture: Wie Sie bessere Entscheidungen im Unternehmen treffen
