

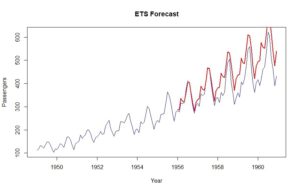
In diesem Blog zeigen wir, wie einfach es ist, Advanced Analytics-Funktionen in R zu nutzen. Wir konzentrieren uns auf verschiedene Diagrammtypen, Regressionsanalysen mit R und Time Series Forcecasts mit R.

Mit der Data Warehouse Cloud Version 2020.14 hat SAP die Einbindung von Zeitdimensionen ermöglicht. Warum ist die Zeitdimension so wichtig? Zuvor waren in den zu ladenden Daten für die SAP Data Warehouse Cloud viele Aggregationsebenen einer Datumsspalte erforderlich, z.B. für eine separate Spalte «Quartal» oder

Business Analytics baut auf guten Daten auf. ☝ SAP bietet verschiedene Lösungen, um das optimale Data Warehouse zu gestalten. ♔ ✅

Sie verwenden Einkaufsdaten in Ihrem Reporting? Profitieren Sie von unserem kostenlosen Template!Sie benötigen weitere Daten? Profitieren Sie von unserer Erfahrung!SAP Data Warehouse Cloud ermöglicht zentrale Datenbestände leicht und intuitiv zu erweitern. Einführung in die SAP Data Warehouse Cloud (DWC) Die SAP Datawarehouse Cloud Lösung ist

Business Analytics einfacher ✅ und effektiver ✅ zu gestalten, ist herausfordernd. Ich stelle mit dieser Blog(serie) meine Lösungsansätze zur Diskussion. ✌

Lange danach gesucht? Jetzt gefunden! Unsere Übersicht von typischen Problemen und Lösungen im Bereich von HANA SQLscript. Die Lösungsmuster reichen dabei von rein sprachlichen Problemen (z.B. „mit welchem Sprachelement ermittle ich den ersten Eintrag“) über formale Probleme (z.B. „wie wandle ich in SQLscript Zeitmerkmale um“)

Administration als aller Analysis Anfang In einem neuen leeren System sind zunächst immer einige administrative Schritte notwendig, zum Glück sind es in der SAP Data Warehouse Cloud nur einige wenige, die man unbedingt erledigen muss. Natürlicherweise beginnt es mit der Userverwaltung. Das Anlegen neuer User

Was ist die SAP Data Warehouse Cloud? Wer einen Blick auf die Zukunft von SAP Produkten werfen möchte, der besitzt mit der Agenda der SAP Teched (https://events.sap.com/teched/en/home) eine ganz brauchbare Glaskugel, zumindest für die nähere Zukunft. Auf dieser Agenda zeigt sich, dass SAP mit Nachdruck

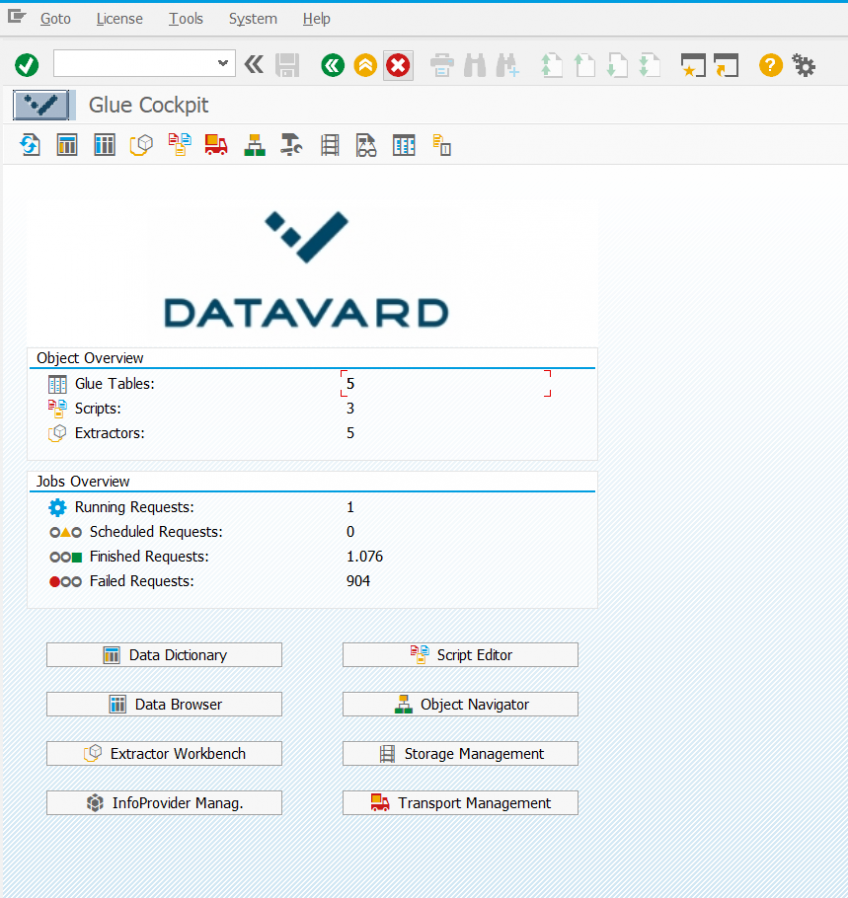
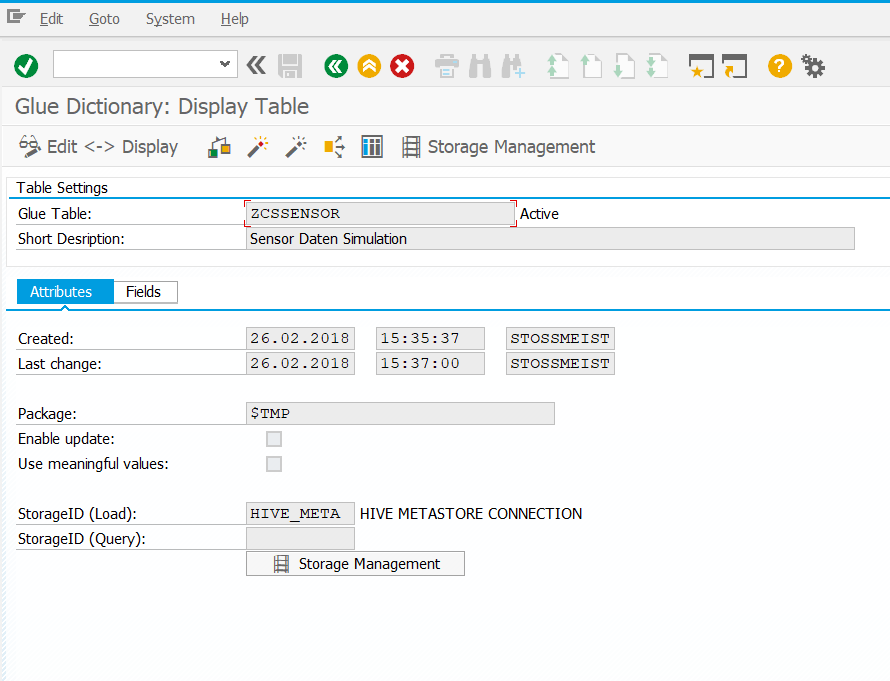
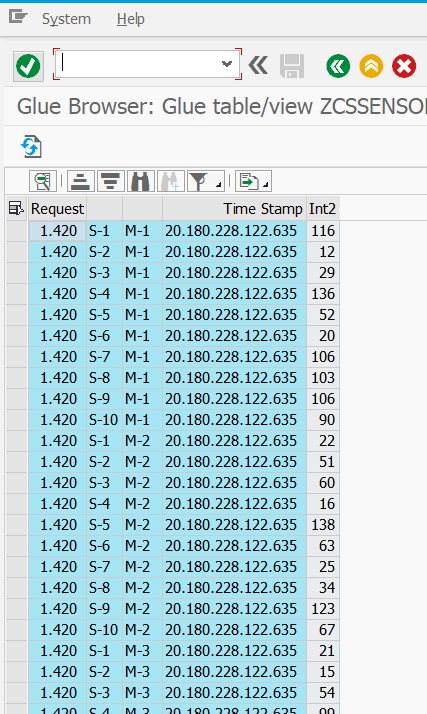
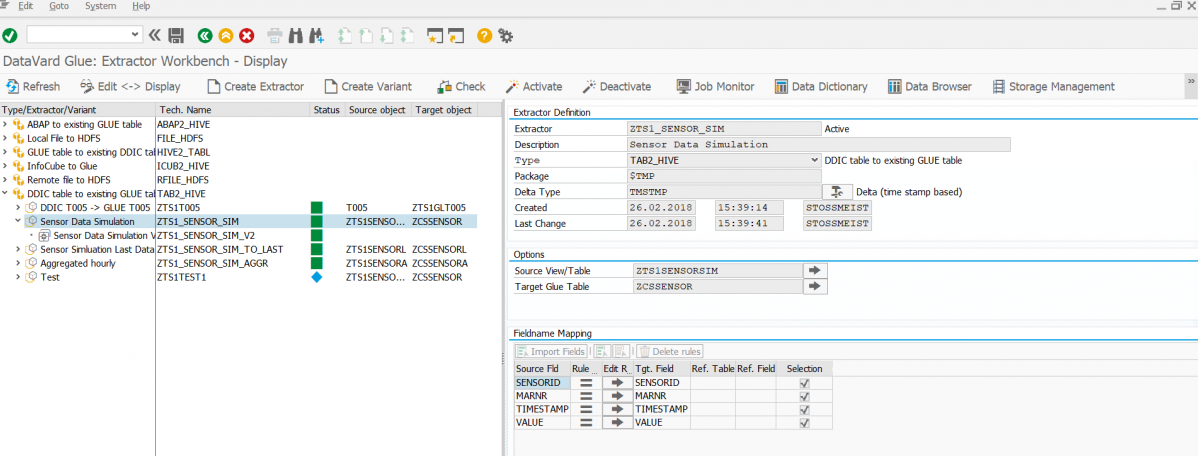
In den vorherigen Teilen dieses Blogs wurde gezeigt, wie die Sensordaten der Fabriksimulation schliesslich als Tabelle (genauer: als Tabellenlink) in der SAP HANA verfügbar gemacht wurde. Der nächste Schritt wäre nun beispielsweise in der HANA einen gescripteten (oder alternativ auch graphischen) CalculationView anzulegen, der die
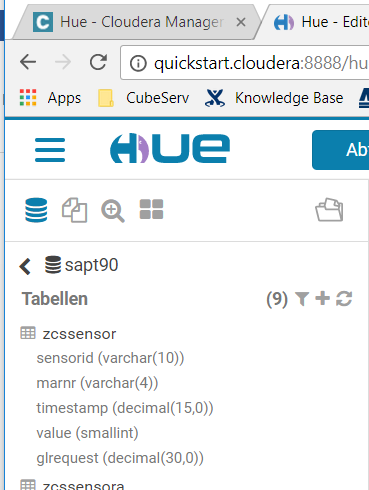
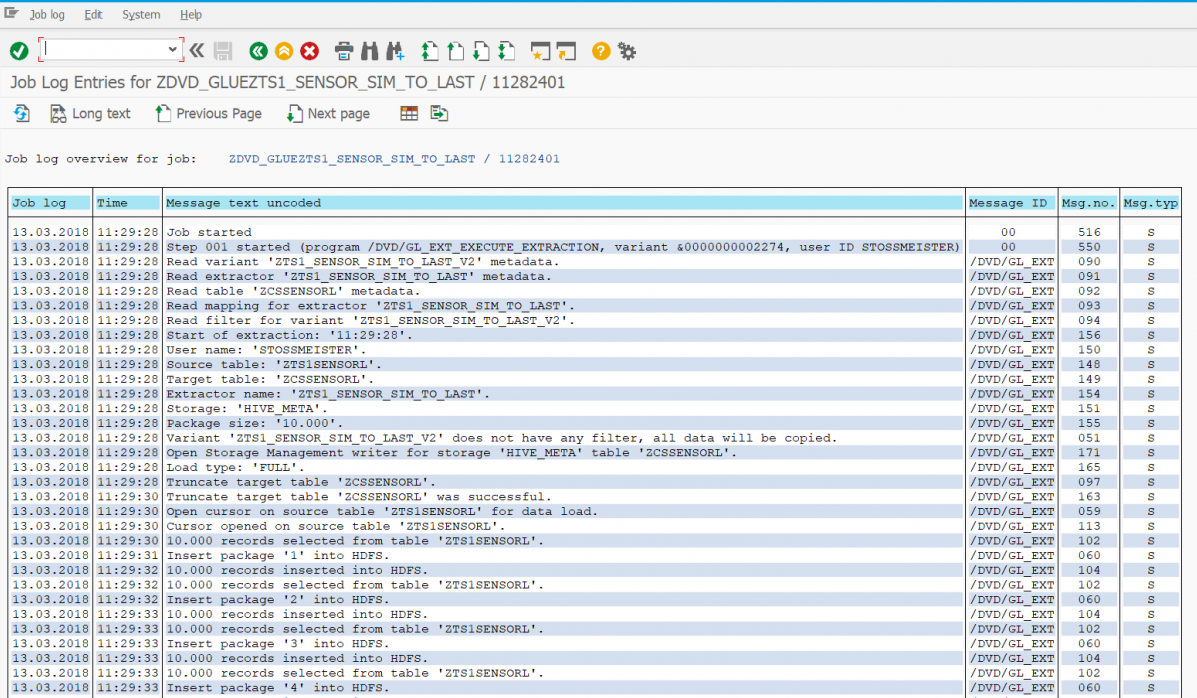
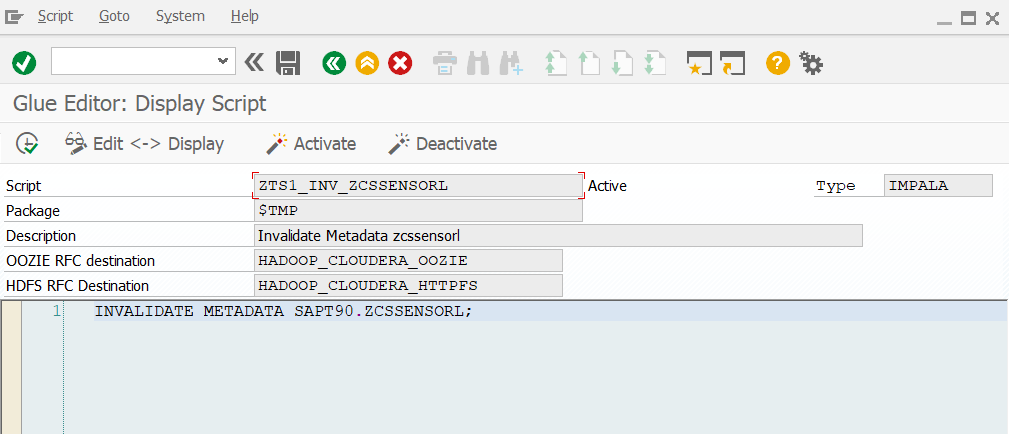
In den beiden vorherigen Teilen dieses Blogs habe ich beschrieben, wie die Fischertechnik-Fabriksimulation Daten in Form eines CSV-Files erzeugt und wie diese Daten in das Hadoop Cluster gelangen und dort sogar als Tabelle zur Verfügung stehen. In diesem Teil geht es nun um die verschiedenen

In den ersten beiden Teilen dieses Blogs haben wir die Fischertechnik Fabriksimulation gezeigt. Diese Fabriksimulation soll nun kontinuierlich Daten erzeugen, die einerseits in einem Big Data-Cluster landen sollen, andererseits mit Mitteln des SAP BW oder mit SAP Analytics for Cloud reportbar sein sollen. Als Big

Im ersten Teil dieses Blogs habe ich die Herausforderungen benannt, die Big Data für ein Data Warehouse darstellt.Für die Big Data-Architektur eines solchen EDW im konkreten Fall eines SAP BW on HANA oder SAP BW/4HANA ergeben sich damit bereits einfache Schlussfolgerungen: Es ist nicht möglich,

Das Internet der Dinge (IoT) ist einer jener Begriffe, die sich inflationär in Nachrichten, Vorträgen und Veröffentlichungen finden und deren häufige Verwendung zum schnellen Überdruss beim geneigten Leser führen. Die natürliche Reaktion auf das Auftreten solcher Modebegriffe ist das Abwarten, ob die Welle nicht genauso