In den ersten beiden Teilen dieses Blogs haben wir die Fischertechnik Fabriksimulation gezeigt. Diese Fabriksimulation soll nun kontinuierlich Daten erzeugen, die einerseits in einem Big Data-Cluster landen sollen, andererseits mit Mitteln des SAP BW oder mit SAP Analytics for Cloud reportbar sein sollen.
Als Big Data-Cluster wurde bei uns eine Cloudera-Installation aufgebaut. Ähnlich wie bei Linux, dem kostenlosen open-Source-Betriebssystem, das man in vorkonfigurierten und dann kostenpflichtigen Versionen erwerben kann (z.B. Suse Linux, RedHat,…), gibt es von Apache Hadoop ebenfalls vorkonfigurierte Installation wie z.B. von Hortonworks oder von Cloudera. Wir haben uns für Cloudera entschieden und haben eine 60-Tage-kostenlose Enterprise Edition installiert. Da es sich nur um eine Demoanwendung handelt, ist es auch ein einfacher Cluster mit nur einem Knoten geworden.
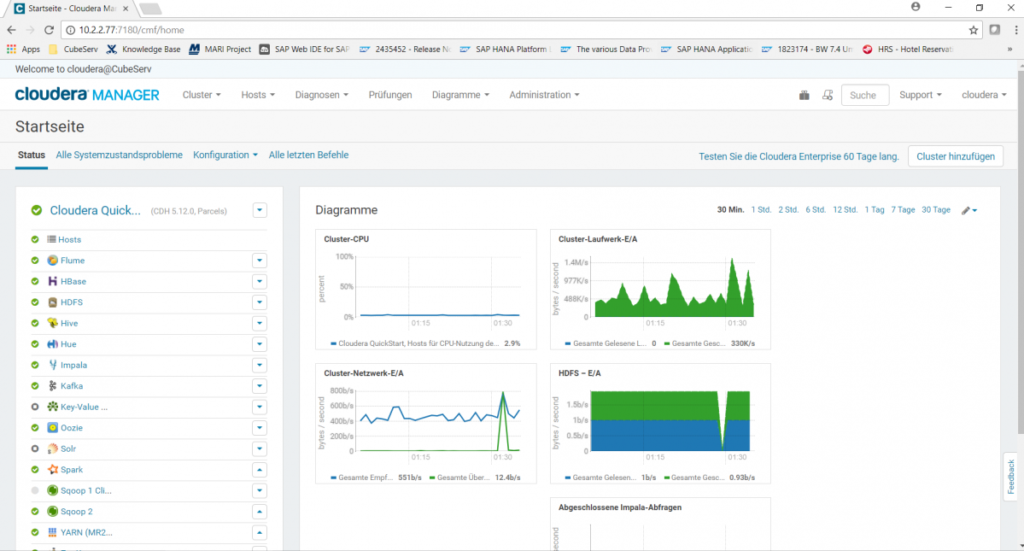
Hadoop kommt mit einer ganzen Reihe von Services daher, die dem Laien erstmal wenig sagen und in ihrer Anzahl und Bedeutung zunächst sehr verwirrend sind.
- HBase ist die Datenbank des Systems.
- HDFS ist das Hadoop Distributed File System, welches Daten redundant speichert und damit hohe Ausfallsicherheit garantiert.
- Hive ist ein Service, der SQL-artige Abfragen gegen die Datenbank des Systems erlaubt.
- Impala ermöglicht schnellere SQL-Abfragen als Hive durch bessere parallele Algorithmen. Impala dient vor allem dem schnellen Lesen und weniger anderen Vorgängen, wie Anlegen, Schreiben oder Ändern.
- Hue ist ein Service, der eine SQL-Abfrage-Workbench und –Visualisierung bietet. Hier kann man z.B. SELECT-Statements ausprobieren (und dabei wählen, ob man über die Hive- oder die Impala-Engine abfragen möchte).
- Kafka ermöglicht das Laden und Exportieren von Datenströmen.
- Oozie ist der Service, mit dem Batch-Jobs eingeplant werden.
- YARN ist die Ressourcen-Verwaltung, die auch die Zuteilung von Abfragen zu Servern steuert.
- Flume ist ein Service, um Logs nach Hadoop zu streamen.
Die Fischertechnik Fabrik wird ja über die Siemens Logo Steuergeräte gesteuert. Die Steuergeräte bzw. ihre Programmieroberfläche bietet nun die Möglichkeit, die Zustände aller vorhandenen Eingänge und Ausgänge in periodischen Abständen (z.B. 1s) in ein Protokollfile wie z.B. Log.csv zu schreiben. Es immer alle Ein- und Ausgänge geschrieben, wir haben uns zunächst aber nur auf drei beschränkt, und zwar die Steuerungen für die Sortier-Rutschen, die weisse, rote und blaue Plastikzylinder voneinander trennen, abhängig von der erkannten Farbe in der Photozelle.
Damit wurde ein möglichst einfacher Bericht aufgebaut, nämlich ein einfacher Zähler, der gezählt hat, wie oft eine 1 vom Motor Q2 (weiss), Q3 (rot) oder Q4 (blau) gemeldet wurde. Dies entsprach dann der entsprechenden Anzahl an durchgelaufenen Plastikgütern.
Die Siemens-Steueroberfläche schreibt also permanent in ein lokales CSV-File auf dem Laptop, mit dem die kleine Anlage gesteuert wird. Dies ist also die Quelle unserer Sensordaten. Auf dem Cloudera-System wurde nun per Samba das Directory, in dem dieses Protokollfile geschrieben wird, gemountet. Damit war aus Sicht des Cloudera-Systems lokal ein CSV-File vorhanden. Gleichzeitig bestand keine Gefahr, dass eine kurzzeitige Unterbrechung der Verbindung zum Abbruch des Schreibvorgangs führt. Das Schreiben lief permanent weiter und sollte die Verbindung via Internet einmal unterbrochen sein, so würden die neuen Daten mit der nächsten Wiederverbindung wieder abholbar sein.
Dieses lokal sichtbare CSV-File, das LogFile.csv, wird nun mit Hilfe eine Flume-Agenten permanent auf ein Ziel in Kafka geschrieben. Die entsprechende Konfigurationsanweisung, die eine Quelle, ein Ziel (Senke) und einen Kanal definiert, lautet wie folgt:
#------------------------------------
tier1.sources = r1
tier1.sinks = k1
tier1.channels = c1
# Describe/configure the source
tier1.sources.r1.type = TAILDIR
tier1.sources.r1.filegroups = f1
tier1.sources.r1.filegroups.f1 = /samba/FischerTechnik/LOG/LogFile.csv
tier1.sources.r1.positionFile = /tmp/flume-position_3.json
# Describe the sink
tier1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
tier1.sinks.k1.topic = sensor_csv
tier1.sinks.k1.brokerList = quickstart.cloudera:9092
tier1.sinks.k1.batchSize = 1
# Use a channel which buffers events in memory
tier1.channels.c1.type = memory
tier1.channels.c1.capacity = 100000
tier1.channels.c1.transactionCapacity = 10000
# Bind the source and sink to the channel
tier1.sources.r1.channels = c1
tier1.sinks.k1.channel = c1
#------------------------------------
Für die Einrichtung dieser Konfiguration nochmal herzlichen Dank an die Experten unserer Partnerfirma für Hadoop-Systeme, die Ultra Tendency GmbH (www.ultratendency.com), und hier speziell an Matthias Baumann, der uns mit seiner Hadoop-Expertise schon einige Mal weitergeholfen hat.
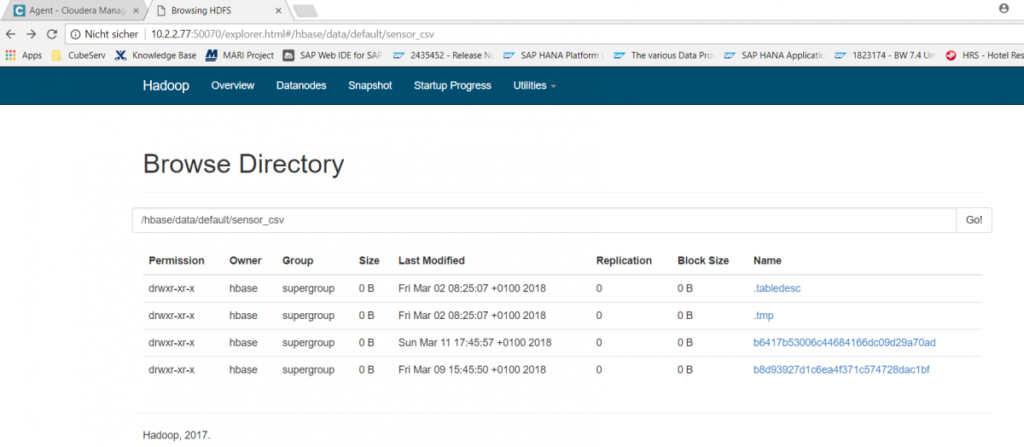
Damit liegt nun im Cloudera im HDFS-Filesystem die Datei sensor_csv vor, die im Sekundentakt neue Daten erhält. Um dieses CSV-File für SQL-Abfragen verfügbar zu machen, wird in Hive folgendes Kommando abgesetzt:
CREATE EXTERNAL TABLE sapt90.zcssensorq (
key varchar(6),
time VARCHAR(8),
value VARCHAR(4),
sensor VARCHAR(20)
)
STORED BY "org.apache.hadoop.hive.hbase.HBaseStorageHandler"
WITH SERDEPROPERTIES (
"hbase.columns.mapping" =
":key,default:time,default:value,default:sensor"
)
TBLPROPERTIES("hbase.table.name" = "sensor_csv")
Dieses Kommando erzeugt eine leere Tabellenhülle zcssensorq (in einem Schema mit dem Namen sapt90) mit 4 Spalten (key, time, value, sensor) und teilt dem System mit, dass der Inhalt dieser Tabelle sich in einer hbase-Tabelle mit dem Namen sensor_csv befindet. Auf diese Weise können nun im Hue-Service einfache Hive- oder Impala-Abfragen gestartet werden, z.B. select * from zcssensorq;:
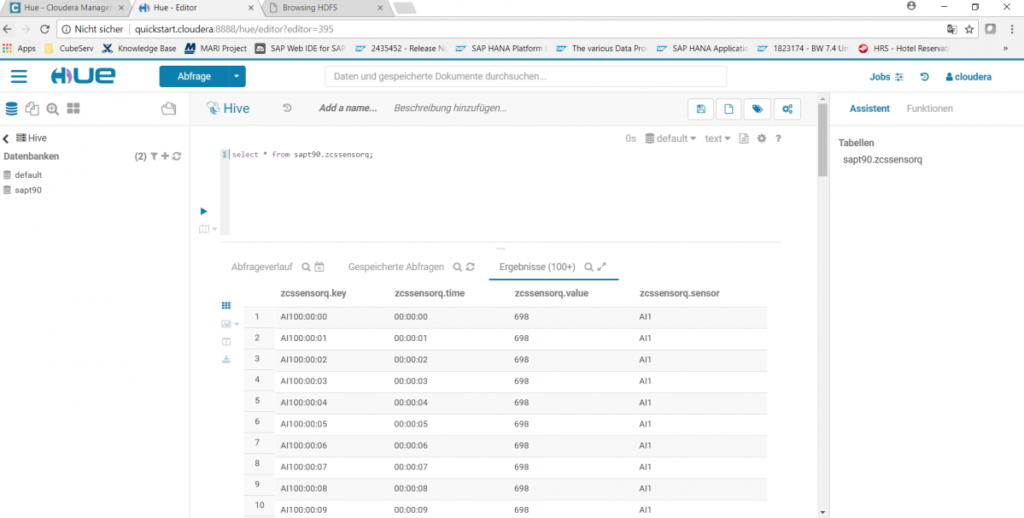
Die Sensordaten der Fischertechnik-Fabrik werden damit kontinuierlich geschrieben und liegen als File bzw. als Tabelle im Hadoop System verfügbar vor. Wie können diese Daten nun für ein Reporting verfügbar gemacht werden? Darum geht es im nächsten Teil dieses Blogs.