In diesem Beitrag wird untersucht, wie strukturierte Daten optimal abgelegt werden sollten, um effizient mit Mircosoft Power BI visualisiert werden zu können.
Versuchsanlage
Die Daten sind in einer lokalen Oracle-Datenbank gespeichert und via einer View abrufbar.
Um die Datenmenge in der View zu skalieren, ist der View eine Tabelle hinzugefügt, welche bei der Abfrage ein kartesisches Produkt bildet. Damit ist es möglich, die Datenmenge auf einfache Weise zu variieren.
Es sollen in der Versuchsanlage einmal rund 100‘000 Datensätze und einmal rund 10 Mio. Datensätze ausgewertet werden.
Zugriff auf die Datenquelle
Untersucht werden folgende Varianten
- V1: Import aus Quellsystem
- V2: Direct Query auf das Quellsystem
- V3: Direct Lake auf ein Lakehouse
- V4: Direkt Lake auf ein Warehouse
Die Auswertungen zu Varianten V1+V2 werden über den Power BI-Client erstellt und dann veröffentlicht.
Bei den Varianten V3+V4 wird erst jeweils ein DataFlow für die Aktualisierung der Daten in MS Data Fabric erstellt und darauf die Auswertung mit Power BI erstellt.
Bei allen Auswertungsvarianten erstellt Power BI jeweils ein semantisches Model.
Das Modell von V1 hält die Daten im Modell und muss eingeplant werden, um die Daten zu aktualisieren. Bei dieser Aktualisierung kann in Modellen, bei welchen garantiert ist, dass ein bestimmter Teil der Daten sich nicht mehr verändert, eine inkrementelle Aktualisierung definiert werden, was den Aktualisierungsvorgang beschleunigen kann. Auf eine inkrementelle Aktualisierung wird bei dieser Untersuchung nicht weiter eingegangen, da alle Daten der Tabelle über die Zeit veränderbar sind.
Das Modell V2 hält keine Daten im Modell. Bei der Aktualisierung wird lediglich die Struktur und die Definitionen im semantischen Modell aktualisiert. Daher ist der Zeitaufwand für eine Aktualisierung sehr klein.
Die Modelle V3+V4 halten ebenfalls Daten im Modell. Diese semantischen Modelle können eingeplant oder bei Aktualisierung des zugrundeliegenden Datentabellen im Lakehouses/Warehouses automatisch nachgeführt werden.
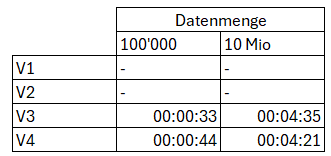
Zeitbedarf für die Aktualisierung des semantischen Layers bei manueller Aktualisierung
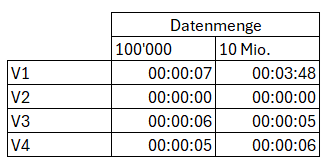
Bei den Modellen V3+V4 kommt zu diesen Zeiten noch die Beladung des Lakehouse/Warehouse hinzu. Diese Beladung wird jeweils initial über einen Dataflow Gen2 beladen und für die Aktualisierung der Daten jeweils über eine Data Pipeline nachgeführt.
Bei der initialen Beladung werden die Daten aus der Quelle überschreibend in die jeweilige Zieltabelle geschrieben.
Dauer der Initial-Beladung
Bei der Aktualisierung der Daten werden alle Daten der Quelle, welche einen neueren Zeitstempel als der maximale Zeitstempel im Ziel haben, in eine temporäre Tabelle geladen und dann die Daten im Ziel mit denjenigen Daten aus der temporären Tabelle aktualisiert.
Hierbei werden die hierzu benötigten Notebooks bei der Lakehouse-Beladung mit Spark SQL, bei der Warehouse-Beladung mit T-SQL umgesetzt
Dauer der Differenz-Beladung
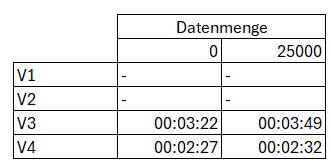
Wir sehen, dass der Overhead bei der Differenz-Beladung beträchtlich ist. Wurde seit dem letzten Load keine Daten verändert, so dauert der Abgleich, notabene von 0 Daten, nur unwesentlich kürzer als ein Update von 25000 Datensätze bei 10 Mio. Datensätzen insgesamt.
Aktualisierung Bericht
Alle Berichte V1-V4 sind mit den identischen Berichtselementen bestückt.

Es wird jeweils die Summe der Area eines Dimensionswertes in einem Kreisdiagramm ausgegeben. Dabei kann nach einer anderen Dimension über den ganzen Bericht gefiltert werden.
Mess-Kriterium hierbei ist der Zeitbedarf, bis der Bericht nach der höchsten Filterausprägung (WSJ-790) gefiltert werden kann.
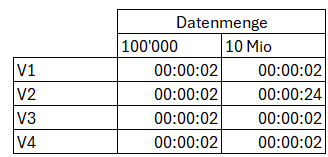
Wir sehen, dass bei 100000 Datensätzen bei allen Reports das Mess-Kriterium identisch ist. Bei 10 Mio. Datensätzen wird aber bei Direkt Query V2 wesentlich mehr Zeit bis zur freien Navigation im Report benötigt.
Gesamt-Ergebnis
Berechnen wir nun die Gesamt-Zeit, welche benötigt wird, um Daten (bei 250000 zu aktualisierende Datensätze) in diesem Bericht zu visualisieren, so kommen wir zu folgender Auflistung:
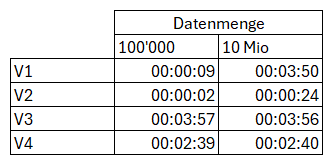
Wir sehen, dass bei kleinen Datenmengen von 100’000 Datensätzen, Import V1 und Direkt Query V2 das optimale Ergebnis liefern. Sollen jedoch grössere Datenmengen in der Größenordnung von 10 Mio. Datensätzen im Report aktualisiert werden, so würde vermeintlich Direkt Query V2 das Rennen machen. Dies stimmt so aber nicht ganz, da, wenn der Endbenutzer den Report öffnet und Filtern will, muss dieser hier am längsten warten. Mit dieser Wartezeit ist bei jedem Aufruf zu rechnen, was bei den Endbenutzern nicht hinzunehmen sein wird.
Daher ist hier auf eine der Varianten V1, V2 oder V3 auszuweichen. Nur diese Varianten werden von den Endbenutzern akzeptiert.
Fazit
Bei kleineren zu visualisierenden Datenmengen bietet sich im Umfeld von Power BI sicher die Varianten mit Direkt Query V2 oder Import der Daten V1 an. Sollen jedoch grosse Datenmengen ausgewertet werden, so ist V2 nicht geeignet, hängt aber sonst etwas von den Vorlieben und Erfahrungen des Entwicklers ab.
Einige Überlegungen hierzu:
Beim Import V1 werden bei jeder Aktualisierung alle Daten aus der semantischen Schicht gelöscht und neu importiert.
Bei der Variante V3 Lakehouse werden strukturierte Daten in ein Schema gepresst, welches auch für unstrukturierte Daten vorgesehen ist.
Die Variante V4 Warehouse ist nach meiner Einschätzung, auch nach meinen Vorlieben der optimale Ablageort der Daten. Zum einen wird ein System verwendet, welches für die vorliegenden strukturierten Daten vorgesehen ist, zum anderen werden nur Daten im Warehouse manipuliert, welche im Source-System auch verändert wurden.
Vereinbaren Sie jetzt Ihren Expert Call. Wir freuen uns über Ihre Nachricht.