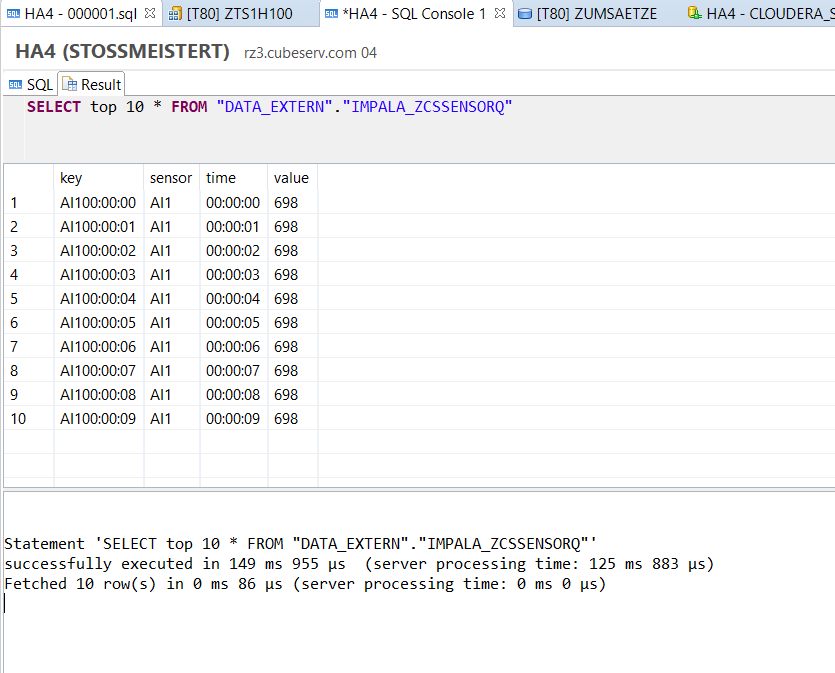
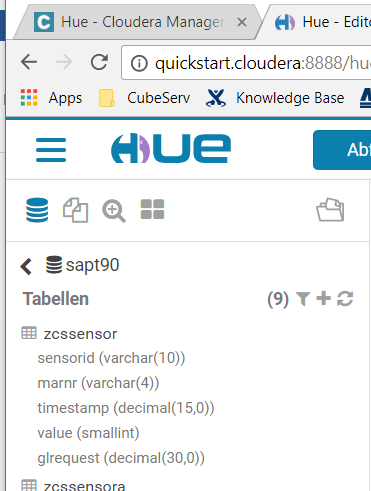
In den vorherigen Teilen dieses Blogs wurde gezeigt, wie die Sensordaten der Fabriksimulation schliesslich als Tabelle (genauer: als Tabellenlink) in der SAP HANA verfügbar gemacht wurde. Der nächste Schritt wäre nun beispielsweise in der HANA einen gescripteten (oder alternativ auch graphischen) CalculationView anzulegen, der die Meldungen der Motoren Q2, Q3 und Q4 in etwa wie folgt liest (am Beispiel Q2):
SELECT count(*) FROM „DATA_EXTERN“.“IMPALA_ZCSSENSORQ“ where „sensor“ = ‚Q2‘ and „value“ = ‚1‘;
Leider sind wir dabei aber gegen einen Bug im SAP-Adapter gelaufen, der Adapter produziert eine fehlerhafte Abfrage mit unsinnigen „N“-Literalen in der Query:
Could not execute ‚SELECT count(*) FROM „DATA_EXTERN“.“IMPALA_ZCSSENSORQ“ where „sensor“ = ‚Q2‘ and „value“ = ‚1“ in 89 ms 673 µs . SAP DBTech JDBC: [403]: internal error: Error opening the cursor for the remote database Failed to execute query [SELECT COUNT(*) FROM `sapt90`.`zcssensorq` `IMPALA_ZCSSENSORQ` WHERE (`IMPALA_ZCSSENSORQ`.`sensor` = N’Q2′) AND (`IMPALA_ZCSSENSORQ`.`value` = N’1‘)]. for query „SELECT COUNT(*) FROM „““sapt90″“.““zcssensorq“““ „IMPALA_ZCSSENSORQ“ WHERE „IMPALA_ZCSSENSORQ“.“sensor“ = ‚Q2‘ AND „IMPALA_ZCSSENSORQ“.“value“ = ‚1‘ „
Dieser Fehler im Impala-Adapter wird bereits im SAP-Hinweis „2562391 – Keine SQL-Abfrage gegen eine virtuelle Impala-Tabelle mit Literalzeichenfolge in der WHERE-Bedingung“ beschrieben. Die Lösung besteht leider in keinem einfachen Patch, sondern der benutze SDI-Agent vom Release 1.0 muss durch eine 2.0-Installation ersetzt werden. Da vorhandene Verbindungen, die diesen Agenten benutzen, dabei verloren gehen und neu angelegt werden müssen, wurde die Installation eines neuen 2.0-Agenten separat vorangetrieben, die Modellierung aber mit dem fehlerhaften 1.0-Agenten fortgesetzt, um doch möglichst schnell einen funktionierenden Prototypen zu erhalten. Da nun gegen die Impala-Adapter keine WHERE-Bedingungen gefeuert werden dürfen und doch Impala wegen der besseren Geschwindigkeit im Vergleich zu Hive verwendet werden sollte, wurde folgendes gemacht:
1. Bereits auf der Hadoop-Seite wurde neben der Tabelle zcssensorq auch die Tabellen zcssensorq2, zcssensorq3 und zcssensorq4 gefüllt, und zwar nur für die Tabellenzeilen, bei denen der Sensorwert = 1 war. Die Tabellen enthalten also nur die Aktiv-Meldungen des entsprechenden Q-Sensors und sonst nichts. Damit müssen nur die Zeilen der Tabelle gezählt werden ohne jede WHERE-Bedingung.
2. Es wurde in der HANA ein CalculationView angelegt, der folgendes Zählen durchführt:
tmp1 = select count( * ) as „COUNT_Q2“ from „DATA_EXTERN“.“IMPALA_ZCSSENSORQ2″;
tmp2 = select count( * ) as „COUNT_Q3“ from „DATA_EXTERN“.“IMPALA_ZCSSENSORQ3″;
tmp3 = select count( * ) as „COUNT_Q4“ from „DATA_EXTERN“.“IMPALA_ZCSSENSORQ4″;
var_out = select „COUNT_Q2“, „COUNT_Q3“, „COUNT_Q4“ from :tmp1, :tmp2, :tmp3;
Leider führt aber selbst dieses WHERE-freie Coding zu einem Abfragefehler aufgrund des Bugs im Impalaadapter. Grund ist, dass die HANA diese Abfrage optimiert und dabei dich wieder WHERE-Bedingungen entstehen. Als Workaround wurde das System gezwungen, diese Optimierung sein zu lassen und die Abarbeitung wirklich sequentiell vorzunehmen. Dies gelang durch die folgenden Befehle, die die entscheidenden Worte „SEQUENTIAL EXECUTION“ enthalten:
drop procedure „_SYS_BIC“.“pg.ccedw.sfb18/ZTS1_CV_SFB_COUNTER_Q24/proc“;
create procedure „_SYS_BIC“.“pg.ccedw.sfb18/ZTS1_CV_SFB_COUNTER_Q24/proc“ ( OUT var_out
_SYS_BIC“.“pg.ccedw.sfb18/ZTS1_CV_SFB_COUNTER_Q24/proc/tabletype/VAR_OUT“ ) language sqlscript sql security definer reads sql data
as
/********* Begin Procedure Script ************/
BEGIN SEQUENTIAL EXECUTION
tmp1 = select count( * ) as „COUNT_Q2“ from „DATA_EXTERN“.“IMPALA_ZCSSENSORQ2″;
tmp2 = select count( * ) as „COUNT_Q3“ from „DATA_EXTERN“.“IMPALA_ZCSSENSORQ3″;
tmp3 = select count( * ) as „COUNT_Q4“ from „DATA_EXTERN“.“IMPALA_ZCSSENSORQ4″;
var_out = select „COUNT_Q2“, „COUNT_Q3“, „COUNT_Q4“ from :tmp1, :tmp2, :tmp3;
END /********* End Procedure Script ************/