Die Azure Data Factory ist ein cloudbasierter, codefreier ETL- und Datenintegrationsservice von Microsoft, der als Platform-as-a-Service (PaaS) fungiert. Ihr Schwerpunkt liegt auf der nahtlosen Integration von Daten aus vielfältigen Quellen in einem zentralisierten Datenspeicher in der Cloud. Dies ermöglicht eine effiziente Verwaltung und Analyse der Daten, unabhängig von ihrer Herkunft. Die codefreie Natur des Services erleichtert die Entwicklung und Wartung von Datenpipelines erheblich.
Ein zentraler Aspekt von Azure Data Factory ist die Zusammenführung von strukturierten und unstrukturierten Daten in einem zentralen Speicher, wodurch die Konsolidierung und Vereinheitlichung erleichtert wird. Durch die Integration mit verschiedenen Cloud-Compute-Services ermöglicht der Service eine flexible und skalierbare Datenverarbeitung. Diese Services werden genutzt, um Transformationen und Analysen auszuführen, was eine optimale Leistung und Skalierbarkeit gewährleistet.

Azure Data Factory Kernkomponenten
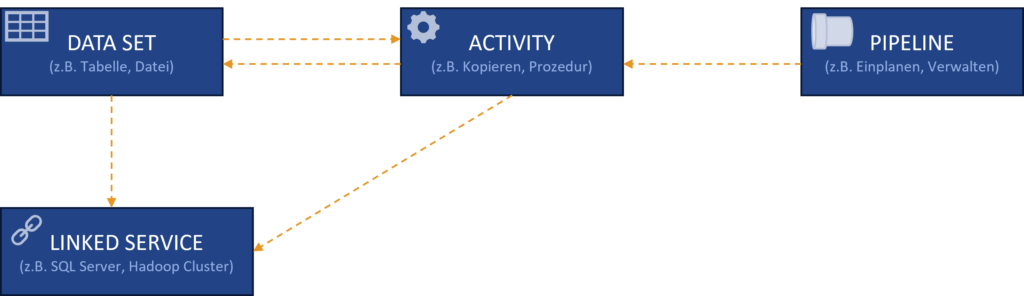
Die Azure Data Factory kann mehrere Pipelines haben, die logische Gruppierungen von Aktivitäten darstellen. Eine Pipeline fasst Aktivitäten zusammen, die gemeinsam eine Aufgabe erfüllen, beispielsweise das Kopieren von Daten von einem SQL Server nach Azure Blob Storage und deren Verarbeitung mit einem Hive-Skript auf einem Azure HDInsight-Cluster. Datasets sind benannte Ansichten von Daten, die auf die in Aktivitäten verwendeten Ein- und Ausgabedaten verweisen. Vor der Erstellung eines Datasets muss ein Linked Service erstellt werden, der die Verbindungsinformationen zu externen Ressourcen definiert. Ein Azure Storage Linked Service verknüpft beispielsweise ein Speicherkonto, während ein Azure Blob Dataset den Blob-Container und Ordner innerhalb dieses Kontos repräsentiert, in dem Eingabe-Blobs für die Verarbeitung liegen. Linked Services sind somit Schlüssel für die Verbindung zwischen der Data Factory und externen Datenspeichern.
SAP Daten in der Azure Data Factory
Hinweis:
Die nach Veröffentlichung dieses Blogs aktualisierte SAP Note 3255746 untersagt die Nutzung von im
Zusammenhang mit ODP stehenden RFC-Modulen, was wiederum auch folgende Ausführungen zum SAP CDC Konnektor in Azure betrifft.
In einem Datenintegrations-Szenario aus SAP- und Non-SAP-Systemen bietet ein modernes Data Warehouse als Lakehouse eine effiziente Lösung.
Die Möglichkeit eines Pushbacks in SAP BW ermöglicht weiteres Verknüpfen und Reporting.
Somit besteht die Möglichkeit der Co-Existenz von Azure Data Factory und beispielsweise einem SAP Business Warehouse.
Übersicht SAP-Konnektoren in Microsoft Azure
Für die Anbindung von SAP-Systemen an die Azure Data Factory stehen verschiedene Konnektoren zur Verfügung. Die folgende Tabelle bietet einen Überblick über diese.

Viele der Konnektoren haben einige Einschränkungen. Darunter fallen Limitierungen in der Funktionalität, der Anzahl unterstützter Objekte oder der Performance. Allerdings bietet nur der SAP CDC Konnektor die Möglichkeit, einen vollwertigen Delta-Load zu realisieren.
Das macht den gerade erwähnten SAP CDC Konnektor besonders interessant, da er auf das Operational Data Provisioning-Framework (ODP) zugreift und somit komplett neue Einsatzzwecke erlaubt.
Im Folgenden werden das ODP-Framework und die Eingliederung des SAP-CDC Konnektors in die Architektur vorgestellt.
Operational Data Provisioning - Framework
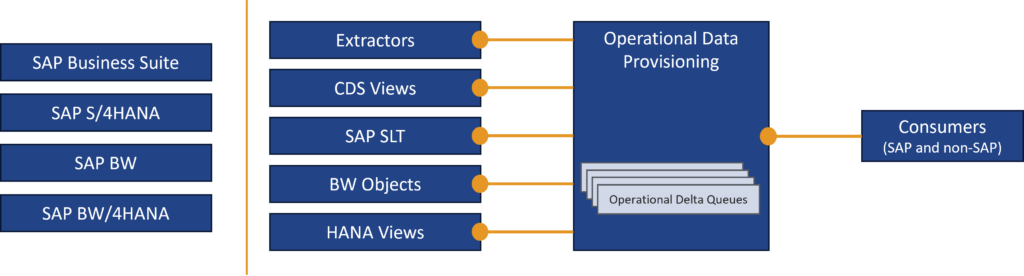
Ziel und Aufgabe des ODP-Frameworks ist das Identifizieren von neuen und geänderten Datensätzen in der Quelle. Dies ist vor allem dann nötig, wenn es sich um sehr große Quelltabellen handelt, bei denen ein regelmäßiger Full-Abzug nicht umsetzbar ist. Das ODP-Framework stellt über die Operational Delta Queues als Datenträger für die Zielsysteme neue und geänderte Datensätze bereit. Ziel können dabei SAP- oder Non-SAP-Systeme sein.
Quellseitig können alle ODP-fähigen Quellen genutzt werden, darunter SAP S/4HANA oder ein SAP BW. Die nachfolgende Abbildung veranschaulicht den Aufbau.
Die Eingliederung in die Microsoft-Architektur zeigt folgende Abbildung:
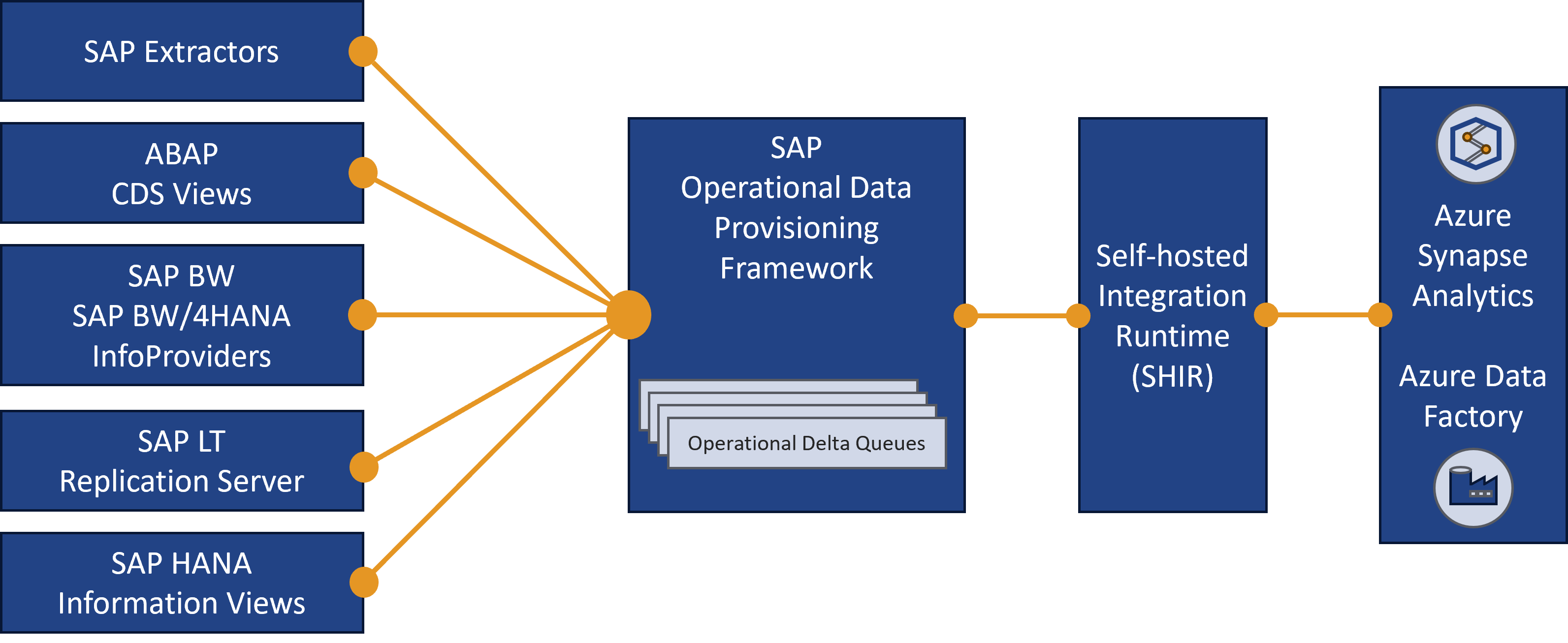
Das SAP Change Data Capture (CDC) nutzt das ODP-Framework für die Echtzeitdatenintegration zwischen SAP und Azure. Die selbstgehostete Integration Runtime fungiert als Bindeglied, gewährleistet eine sichere Verbindung und ermöglicht den Datenaustausch in Echtzeit. SAP DataSources dienen als Provider, während Azure Dataflows als Abonnent der Operational Delta Queues auftreten. Diese Struktur ermöglicht eine effiziente Erfassung und Verarbeitung.
SAP bietet für die Nutzung ihres ODP-Frameworks durch Drittanbieter-Produkte keinen Support an (siehe SAP Note 3255746). Allerdings wird der CDC-Adapter durch Microsoft offiziell bereitgestellt und natürlich dementsprechend von dem Hersteller weiterentwickelt und gewartet, so dass eine entsprechende Unterstützung im Fehlerfall zur Verfügung steht.
Beispielszenario
Dieses Kapitel soll ein konkretes Szenario für die Nutzung des SAP CDC Konnektors in der Microsoft Azure Data Factory zeigen. Als Datenbasis dienen Vertriebsbelege aus dem S/4HANA und CRM Daten aus Hubspot, für das Microsoft ebenfalls einen Konnektor bereitstellt.
S/4HANA Datenverarbeitung

Als Basis dient ein CDS-View, der die nötigen Information aus den verschiedenen Tabellen quellseitig bereitstellt. Dies erspart das Joinen von Daten in der Azure Data Factory. Dies ist zwar möglich, allerdings deutlich zeitaufwändiger im Vergleich zur Aufbereitung im S/4.
In der Azure Data Factory wird dann ein Datenfluss angelegt, bestehend aus einem Quell- und Senkendataset. Das Quelldataset beinhaltet die Informationen zum ODP-Kontext.

Im Azure Data Factory Datenfluss wird dann der Kopiervorgang vom Quelldataset (S/4HANA ODP-Verbindung) in das Senkendataset (SQL-Tabelle) definiert. In den Einstellungen wird hier auch die Deltaausführung eingestellt.
Im Anschluss wird der erzeugte Datenfluss in eine Azure Data Factory Pipeline eingefügt. Diese Pipeline kann händisch im Debugging-Modus ausgeführt oder periodisch eingeplant werden für den Produktivbetrieb. Als Ergebnis wird die im Senkendataset definierte Tabelle auf dem SQL-Server befüllt.
Hubspot Datenverarbeitung

Hubspotseitig werden Deals und Opportunities in die Azure Data Factory geladen. Der Hubspot-Connector basiert auf der REST-API, ist aber schon vorkonfiguriert. Zu beachten ist, dass die Daten in einem Sternschema gespeichert werden. Um die Kundennummern zu den Deals zu bekommen, müssen also noch Mappingtabellen hinzugezogen werden. Das Pivotieren der Tabellen und das Hinzujoinen passiert dann im Datenfluss.
Die Pipeline hat die gleich Funktion wie bei der S/4 Datenverarbeitung. Die Daten liegen nach der Ausführung in der definierten Tabelle auf dem SQL-Server.
Weiterverwendung
Nachdem jetzt beide Daten bereitliegen, können diese für das Reporting verwendet werden.
Dies kann beispielsweise direkt in Microsoft Power BI passieren oder über einen Umweg im Azure Analysis Services. Hierbei handelt es sich um eine InMemory Datenbank von Microsoft, welche dann nativ in Microsoft Power BI eingebunden werden kann.
Da die Daten in einer SQL-Datenbank abliegen können, aber auch andere Front-Ends zum Einsatz kommen.
Fazit
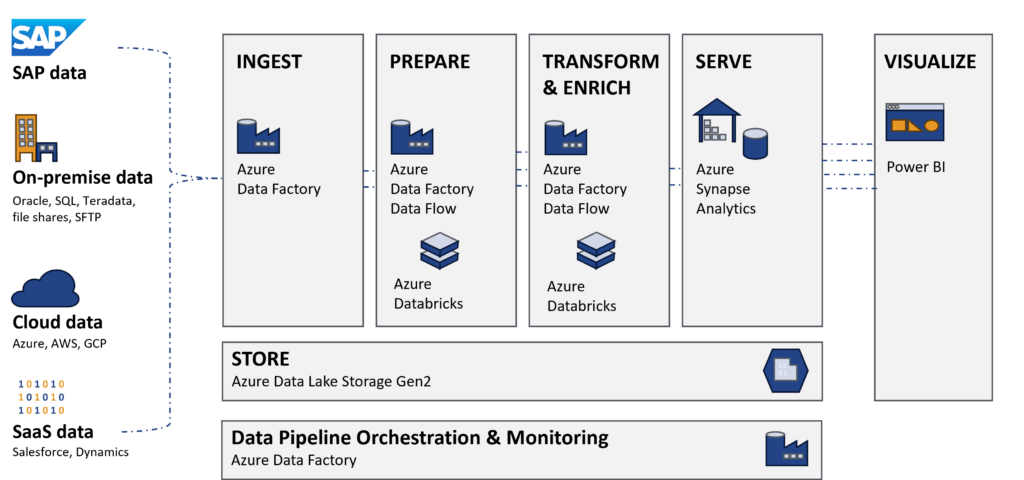
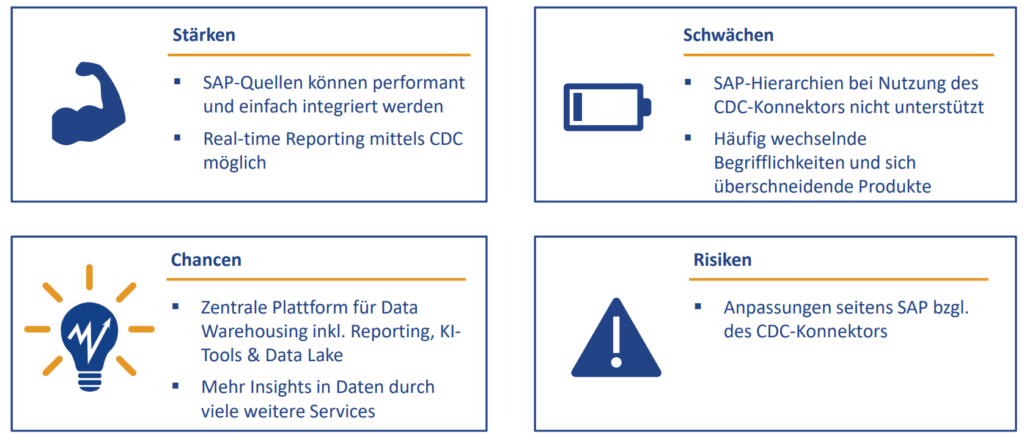
Das Beispiel zeigt, dass mit dem SAP-CDC Konnektor und der Azure Data Factory schnell und codefrei Datenmodelle mit SAP- und Non-SAP-Daten aufgebaut werden können. Weitere Informationen für die Einordnung bietet die folgende Abbildung.
Ausblick
Microsoft hat seine eigene Data Fabric names „Microsoft Fabric“ vorgestellt. Dabei handelt es sich um eine umfassende All-in-One SaaS-Lösung für modernes Data Warehousing (DWH). Derzeit in der Previewphase, bietet es spezialisierte Produktkomponenten, wobei einige, wie Data Factory, sich von der Standalone-Version unterscheiden. Trotz seiner Entwicklungsphase verspricht Fabric eine effiziente Lösung für umfassendes Datenmanagement und moderne Data-Warehouse-Anforderungen.
Der hier vorgestellte SAP-CDC Konnektor ist aktuell noch nicht verfügbar in der Data Factory innerhalb des Microsoft Fabrics.
https://learn.microsoft.com/de-de/fabric/get-started/microsoft-fabric-overview
Innerhalb der SAP Welt bietet das Softwareunternehmen mit der Cloud Data Warehousing Lösung „SAP DataSphere“ ebenso die Möglichkeit, Daten mittel ODP im CDC Modus zu extrahieren. Hierzu werden so genannte Replication Flows eingesetzt, welche die Steuerung und den Datentransport organisieren.
Vereinbaren Sie jetzt Ihren Expert Call. Wir freuen uns über Ihre Nachricht.