Lange danach gesucht? Jetzt gefunden!
Unsere Übersicht von typischen Problemen und Lösungen im Bereich von HANA SQLscript.
Die Lösungsmuster reichen dabei von rein sprachlichen Problemen (z.B. „mit welchem Sprachelement ermittle ich den ersten Eintrag“) über formale Probleme (z.B. „wie wandle ich in SQLscript Zeitmerkmale um“) bis zu applikatorischen Anforderungen (z.B. „wie lese ich in SQLscript Stammdaten nach“).
Die Lösungsmuster erheben nicht den Anspruch, die alleinige oder beste Lösung eines Problems zu sein, sondern sollen als Kopiervorlage dienen und Sie mit verschiedenen Lösungsansätzen inspirieren. Ihr Feedback zu Verbesserungen, Alternativen und Ergänzungen ist jederzeit willkommen!
Das Coding-Beispiel ist so formuliert, wie es typischerweise in einer AMDP-Routine vorkommen könnte. Diese Formulierung kann allerdings in einem HANA-Studio-SQL-Fenster oder im SQL-Editor der ABAP-Transaktion DBACOCKPIT nicht verwendet werden (da dort nicht definiert ist, was die inTab sein soll). Es ist daher an einigen Stellen auch ein Coding-Beispiel angegeben, das man im SQL-Fenster verwendet könnte. In diesen Beispielen sind zusätzliche Zeilen, die die Beispieldaten aufbauen.
Grundlegende Sprachelemente:
- Initialwerte
- Temporäre Tabellen (Tabellenvariablen)
- Umbenennen von Spalten
- Vereinigung gleicher Tabellen
- Join zweier Tabellen
- Fallunterscheidung
- Variable definieren, füllen und benutzen
- NULL-Werte vermeiden
- Anzahl Zeilen zählen
- Bedingungen
- Summe, Max, Min, …
- Führende 0en ersetzen
- Prüfung auf Ziffern
- Verdichten von Leerzeichen
- Entfernen ungültiger Zeichen
- Ersten Datensatz ermitteln
- Rang ermitteln
- Zugriff auf vorherige oder nachfolgende Zeile
Applikatorische Lösungen:
Initialwerte
Beschreibung
Zeichenartige Spalten mit “ initalisieren, Nummern mit 0.
Coding Beispiel
outtab =
SELECT
'' AS "/BIC/STRASSE",
0 AS "/BIC/HAUSNR"
FROM :intab; Eine ähnliche Formulierung erzeugt Beispieldaten, die dann weiterverwendet werden können.
Coding Beispiel SQL-Editor
SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY; Temporäre Tabellen (Tabellenvariablen)
Beschreibung
Tabellen werden dynamisch zur Laufzeit definiert, wenn sie mit einem Select gefüllt werden.
Anmerkung
Tabellenvariablen müssen nicht vor der Benutzung deklariert werden. In der weiteren Verwendung muss dem Namen aber ein „:“ vorangestellt werden.
Coding Beispiel
tmptab = SELECT * FROM :intab;
tmptab2 = SELECT * FROM :tmptab;
outtab = SELECT * from :tmptab2;
Tabellenvariablen sind ein Beispiel dafür, wo sich SQL von SQLscript unterscheidet. Diese Variablen sind Teil der SQLscript-Sprache, aber nicht der SQL-Sprache.
Um sie daher in einem SQL-Fenster verwendet zu können, muss ein sogenannten anonymer Block eingefügt werden.
Das letzte SELECT in folgendem Beispiel erzeugt dann die Ausgabe des Resultats des SQL-Fensters. Ohne diese Zeile wird das Statement zwar ausgeführt, es gibt aber kein Ergebnis. Mehrere solcher SELECTs am Ende erzeugen auch mehrere Resultats-Fenster im SQL-Editor des HANA Studios.
Coding Beispiel SQL-Fenster
DO
BEGIN
tmptab = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY;
tmptab2 = SELECT "SPALTE_A" FROM :tmptab;
SELECT * FROM :tmptab2; -- Tabelle als Resultat ausgeben
END; Umbenennen von Spalten
Beschreibung
Eine oder mehrere Spalten soll einen anderen Namen erhalten.
Coding Beispiel
outtab =
SELECT "ALTER_SPALTENNAME" AS "NEUER_SPALTENNAME" FROM :inTab; Coding Beispiel SQL-Fenster
DO
BEGIN
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY;
SELECT * FROM :tab1; -- Resultat Tabelle mit SPALTE_A
SELECT "SPALTE_A" AS "NEUE_SPALTE" FROM :tab1; -- Resultat umbenannt
END; Vereinigung zweier strukturgleicher Tabellen
Beschreibung
Es wird die Vereinigungsmenge zweier Tabellen gebildet. Die Tabellen müssen dabei von identischer Struktur sein.
Coding Beispiel
outtab =
SELECT columns FROM :TAB1
UNION ALL
SELECT columns FROM :TAB2; Coding Beispiel SQL-Fenster
DO
BEGIN
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY;
tab2 = SELECT * FROM :tab1; -- 2. Tabelle mit Daten
tab3 = SELECT * FROM :tab1
UNION ALL
SELECT * FROM :tab2;
SELECT * FROM :tab3; -- Resultat ausgeben
END; Join zweier Tabellen
Beschreibung
Es wird der Join zweier Tabellen gebildet.
Coding Beispiel
outtab =
SELECT T1.*, T2.* FROM :TAB1 AS T1
LEFT OUTER JOIN :TAB2 AS T2
ON T1.SPALTE_A = T2.SPALTE_X AND
T1.SPALTE_B = T2.SPALTE_Y;
Coding Beispiel SQL-Fenster
DO
BEGIN
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY;
tab2 = SELECT 'A' AS "SPALTE_X",
'C' AS "SPALTE_Y",
2 AS "MENGE"
FROM DUMMY;
tab3 = SELECT T1.*, T2.* from :tab1 AS T1
LEFT OUTER JOIN :tab2 AS T2
ON T1."SPALTE_A" = T2."SPALTE_X";
SELECT * FROM :tab3; -- Resultat ausgeben
END; Fallunterscheidung
Beschreibung
Sie können bereits im SELECT-Statement in der zu ermittelnden Spalte eine Fallunterscheidung machen mit Hilfe von CASE.
Coding Beispiel
outtab =
SELECT
CASE BUCHUNGSART
WHEN 'HABEN' THEN BETRAG
WHEN 'SOLL' THEN -1 * BETRAG
ELSE 0
END AS BETRAG_VZ
FROM :intab; Dieses Statement ist gleichwertig zu folgender Version:
outtab =
SELECT
CASE
WHEN BUCHUNGSART = 'HABEN' THEN BETRAG
WHEN BUCHUNGSART = 'SOLL' THEN -1 * BETRAG
ELSE 0
END AS BETRAG_VZ
FROM :intab; In der 2. Formulierung hat man mehr Freiheit, in der WHEN-Bedingung auch komplexere Bedingungen zu formulieren, z.B.:
outtab =
SELECT
CASE
WHEN BUCHUNGSART = 'HABEN' AND
NOT ( STORNOFLAG = 'X' )
THEN BETRAG
WHEN BUCHUNGSART = 'HABEN' AND
STORNOFLAG = 'X'
THEN 0
WHEN BUCHUNGSART = 'SOLL' THEN -1 * BETRAG
ELSE 0
END AS BETRAG_VZ
FROM :intab; Coding Beispiel SQL-Fenster
DO
BEGIN
tab1 = SELECT 'HABEN' AS "BUCHUNGSART", 1.5 AS "BETRAG" FROM DUMMY
UNION ALL
SELECT 'SOLL' AS "BUCHUNGSART", 2.5 AS "BETRAG" FROM DUMMY;
tab2 = SELECT "BUCHUNGSART", "BETRAG",
CASE
WHEN "BUCHUNGSART" = 'HABEN' THEN "BETRAG"
WHEN "BUCHUNGSART" = 'SOLL' THEN -1 * "BETRAG"
ELSE 0
END AS "BETRAG_VZ"
FROM :tab1;
SELECT * FROM :tab2; -- Resultat ausgeben
END; Variable definieren, befüllen und benutzen
Beschreibung
Sie können lokale Variablen definieren. Diese lassen sich einerseits mit SELECT-Statements befüllen, andererseits kann ihr Inhalt auch wieder per SELECT ausgelesen werden oder sie können in CASE-Anweisungen verwendet werden.
Coding Beispiel
DECLARE lv_tvarvc STRING;
SELECT DISTINCT LOW INTO lv_tvarvc
FROM "TVARVC"
WHERE "NAME" = 'my_setting';
outtab =
SELECT :lv_tvarvc AS TVARVC, * FROM intab; Coding Beispiel SQL-Fenster
DO
BEGIN
DECLARE lv_tvarvc STRING;
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY;
SELECT 'Value1' INTO lv_tvarvc FROM DUMMY;
SELECT :lv_tvarvc, * FROM :tab1; -- Resultat ausgeben
END; NULL-Werte vermeiden
Beschreibung
Werden z.B. in einem Left-Outer-Join in der verjointen Tabelle keine passenden Treffer gefunden, so enthalten die selektierten Spalten dieser Tabelle als Ergebnisse NULL-Werte. Diese Werte sind recht unangenehm, z.B. weil sie im ABAP auch keinem Initialwert entsprechen. Daher sollten solche NULL-Werte immer mit der Funktion COALESCE abgefangen werden. COALESCE(A,B) gibt den Wert A zurück, wenn A nicht NULL ist, ansonsten B. Somit kann man mit B immer einen Ersatzwert angeben, der anstelle von NULL zurückgegeben werden soll.
Alternativ kann man auch mit der Funktion IFNULL arbeiten.
Anmerkung
Ein Codingbeispiel findet sich im Abschnitt Datumsrechnung.
Anzahl Zeilen zählen
Beschreibung
Sie können mit Hilfe des COUNT-Operators die Zeilen zählen lassen. Sie können aber auch ermitteln, wie oft Merkmale jeweils vorkommen, ob z.B. nur einmal oder auch mehrfach.
Hier geben wir nur ein Beispiel für die SQL-Konsole an, die Syntax ist dann leicht auf Anwendungsfälle im AMDP übertragbar.
Coding Beispiel SQL-Fenster
DO
BEGIN
DECLARE lv_anz_zeilen INT;
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY
UNION
SELECT 'A' AS "SPALTE_A",
'C' AS "SPALTE_B",
2.5 AS "BETRAG"
FROM DUMMY;
SELECT COUNT( * ) INTO lv_anz_zeilen FROM :tab1; -- Gesamtzahl als
-- lokale Variable
tab2 = SELECT COUNT ( * ) AS "COUNTER" FROM :tab1; -- Gesamtzahl als Tabelle
SELECT :lv_anz_zeilen AS "Gesamtzahl",
COUNT(*) AS "Anzahl pro Merkmal SPALTE_A",
"SPALTE_A" FROM :tab1
GROUP BY "SPALTE_A"; -- Ausgabe 1, auch wieviele Ausprägungen SPALTE_A
SELECT * from :tab2; -- Ausgabe 2
END; Bedingungen
Beschreibung
Mit Hilfe von IF können Bedingungen formuliert werden.
Anmerkung
Überraschend häufig lassen sich IF-Statements durch CASE-Anweisungen im SELECT ersetzen. Diese passen besser dazu, die Daten immer massenweise zu prozessieren. Durch IF werden gerne wieder Einzelfälle betrachtet, was man vermeiden sollte, um gute Performanz zu erhalten.
Coding Beispiel
DO
BEGIN
DECLARE lv_anz_zeilen INT;
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY
UNION
SELECT 'A' AS "SPALTE_A",
'C' AS "SPALTE_B",
2.5 AS "BETRAG"
FROM DUMMY;
SELECT COUNT( * ) INTO lv_anz_zeilen FROM :tab1; -- Gesamtzahl
IF :lv_anz_zeilen > 0 THEN
SELECT 'Tabelle ist nicht leer' AS "TEXT" from DUMMY;
ELSE
SELECT 'Tabelle ist leer' AS "TEXT" from DUMMY;
END IF;
END; Summe, Max, Min, ...
Beschreibung
Aggregationen wie Summenbildung, Maximum einer Spalte o.ä. können wieder direkt im SELECT-Statement gebildet werden.
Anmerkung
Die Spalten, über die hinweg die Aggregatsfunktion gebildet wird, müssen in einer GROUP-BY-Klausel stehen. I.a. sind das also alle Spalten ausser denen, auf denen die Summe, das Maximun o.ä. gebildet werden soll.
Coding Beispiel
DO
BEGIN
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY
UNION
SELECT 'A' AS "SPALTE_A",
'C' AS "SPALTE_B",
2.5 AS "BETRAG"
FROM DUMMY;
SELECT "SPALTE_A", MAX( "BETRAG" ) AS MAX FROM :tab1
GROUP BY "SPALTE_A"; -- Max pro Ausprägung SPALTE_A
SELECT "SPALTE_B", MAX( "BETRAG" ) AS MAX FROM :tab1
GROUP BY "SPALTE_B"; -- Max pro Ausprägung SPALTE_B
END; Führende 0en ersetzen
Beschreibung
Mit Hilfe des LTRIM-Operators können führende 0en ersetzt werden.
Anmerkung
Der LTRIM-Operator kann auch eingesetzt werden, um z.B. führende Leerzeichen zu eliminieren.
Coding Beispiel
SELECT LTRIM( BPARTNER, '0') AS BP FROM :intab; Coding Beispiel SQL-Fenster
SELECT LTRIM( '00001234', '0') AS BP FROM DUMMY; Prüfung auf Ziffern
Beschreibung
Sie können Spalten daraufhin prüfen, ob nur Ziffern in ihnen vorkommen (z.B. Datumsfelder im internen ABAP-Format).
Anmerkung
Im Beispiel werden die Datensätze selektiert und markiert, die etwas enthalten, das keine Ziffer ist.
Coding Beispiel
SELECT DATUM, 'X' AS MARKIERUNG FROM :intab
WHERE DATUM LIKE_REGEXPR '[^0-9]'; Verdichten von Leerzeichen
Beschreibung
Sie können führende, schliessende, aber auch mittige Leerzeichen entfernen lassen durch Verwendung des sehr mächtigen Operators REPLACE_REGEX.
Coding Beispiel
SELECT REPLACE_REGEXPR ('[\s]' in 'ABC DEF') FROM DUMMY; Entfernen ungültiger Zeichen
Beschreibung
Sie können für das BW ungültige Zeichen entfernen lassen durch Verwendung des sehr mächtigen Operators REPLACE_REGEX in Kombination mit einem Ausdruck, der alle nicht druckbaren Zeichen aus einem Text entfernt.
Die erste Coding-Variante entfernt alle nicht-druckbaren Zeichen, zu denen leider aber auch z.B. die deutschen Umlaute zählen. Falls das nicht gewünscht ist, entfernt die zweite Variante nur gewisse unsichtbare Steuerzeichen plus das Zeichen für geschütztes Leerzeichen (Hex A0).
Coding Beispiel
SELECT REPLACE_REGEXPR( '([^[:print:]])' IN 'TEXT' WITH '' OCCURRENCE ALL ) FROM DUMMY;
SELECT REPLACE_REGEXPR( '([[:cntrl:]\x{00A0}])' IN 'TEXT' WITH '' OCCURRENCE ALL ) FROM DUMMY; Ersten Datensatz ermitteln
Beschreibung
Mit Hilfe von MAX- oder MIN-Funktionen lassen sich neueste oder älteste Datümer ermitteln. Man kann aber auch den ersten Datensatz einer bestimmten Reihe ermitteln, z.B. den BusinessPartner mit frühestem Änderungsdatum.
Anmerkung
Analog kann man natürlich auch den letzten Datensatz ermitteln mit LAST_VALUE.
Coding Beispiel
SELECT FIRST_VALUE( BPARTNER ORDER BY CHANGED_ON ) FROM :intab;
SELECT BPARTNER, LAST_VALUE ( AMOUNT ORDER BY CHANGED_ON ) AS AMOUNT FROM :intab
GROUP BY BPARTNER; Rang ermitteln
Beschreibung
Sie können mit Hilfe der RANK-Funktion Daten eine Rangnummer zuweisen. Dies ist eine Art Sortiernummer, hat aber den Vorteil, dass die Daten dazu nicht sortiert oder umsortiert werden müssen.
Anmerkung
Das kann man z.B. dazu verwenden, um die letzte Position zu einem Beleg zu ermitteln.
Coding Beispiel
tab1 = SELECT *,
RANK() OVER ( PARTITION BY intab."BELEGNUMMER" ORDER BY intab."POSITION" DESC )
AS ZEILENNUMMER_ABSTEIGEND
FROM :intab;
tab2 = select * from :tab1
where ZEILENNUMMER_ABSTEIGEND = 1; Zugriff auf vorherige oder nachfolgende Zeilen
Beschreibung
Wenn Sie jeweils Zeilen einer Tabelle mit der vorherigen oder nachfolgenden Zeile vergleichen wollen, führt das gerne dazu, dass man einen Cursor öffnet und eine Schleife programmiert. Das ist prinzipiell möglich, aber es widerspricht dem Paradigma, die Daten möglichst massenhaft zu prozessieren, um optimale Performanz zu erhalten.
Eine Möglichkeit wäre, die Tabelle mit sich selbst um eine Zeile versetzt zu verjoinen, damit wäre ein Vergleich innerhalb einer (dann doppelt so breiten) Zeile möglich.
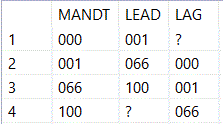
HANA SQLscript bietet aber mit den LEAD- und LAG-Funktionen eine Möglichkeit, auf die entsprechenden Zeilen zuzugreifen.
Anmerkung
Das Beispiel listet die Mandanten eines Systems. In der ersten Spalte die normale Auflistung, in der zweiten wird mit Lead auf die nächste Zeile der Tabelle vorgegriffen, mit Lag auf die vorherige zurückgegriffen.
Coding Beispiel
select MANDT,
LEAD( MANDT ) OVER ( ORDER BY MANDT ) AS LEAD,
LAG( MANDT ) OVER ( ORDER BY MANDT ) AS LAG
FROM T000;
Ergebnis
Datumsrechnung
Beschreibung
Aus Kalendertag sollen die anderen Merkmale (Woche, Monat, Jahr,…) hergeleitet werden.
Anmerkung
In der HANA müssen einmalig die Zeittabellen gefüllt werden (→ Modeler Perspektive), sonst sind die Tabellen leer.
Alternativ können die Tabellen auch mit MDX-Kommandos wie
MDX UPDATE TIME DIMENSION … oder MDX UPDATE FISCAL CALENDAR …
befüllt werden. Dabei darauf achten, was die feinste Granularität sein soll (z.B. Tag oder Sekunde).
Wird nichts gefunden, wird auf den 01.01.2020 zurückgefallen (das war ein Mittwoch, Weekday = 3, daher dieser Wert).
Coding Beispiel
-- UDATE bitte durch das entsprechende Zeitmerkmal ersetzen
SELECT
COALESCE( I.UDATE, '20200101' ) AS CALDAY,
COALESCE( TO_NVARCHAR( T.DAY_OF_WEEK_INT + 1 ), '3' ) AS WEEKDAY1,
COALESCE( T.CALMONTH, '01' ) AS CALMONTH,
COALESCE( T.CALWEEK, '202001' ) AS CALWEEK,
COALESCE( T.MONTH, '01' ) AS CALMONTH2,
COALESCE( T.CALQUARTER, '20201' ) AS CALQUARTER,
COALESCE( TO_NVARCHAR( T.QUARTER_INT ), '1' ) AS CALQUART1,
CASE
WHEN COALESCE( T.QUARTER_INT, 1 ) = 1 OR
COALESCE( T.QUARTER_INT, 1 ) = 2 THEN
'1'
ELSE
'2'
END AS HALFYEAR1,
COALESCE( T.YEAR, '2020' ) AS CALYEAR,
FROM :intab AS I
LEFT OUTER JOIN "_SYS_BI"."M_TIME_DIMENSION" AS T
ON I.UDATE = T.DATE_SAP; Herleitung eines aktuellen UTC-Zeitstempels
Beschreibung
In einer AMDP-Routine soll der aktuelle UTC-Zeitstempel ermittelt werden.
Anmerkung
Beispielcoding für eine AMDP-Feldprozedur.
Coding Beispiel
METHOD PROCEDURE BY DATABASE PROCEDURE FOR HDB LANGUAGE SQLSCRIPT OPTIONS READ-ONLY.
outtab =
SELECT to_nvarchar(current_utctimestamp, 'YYYYMMDDHH24MISS') AS "ETL_TIMESTAMP",
record,
sql__procedure__source__record
FROM :intab;
errortab =
SELECT '' AS "ERROR_TEXT" ,
'' AS "SQL__PROCEDURE__SOURCE__RECORD"
FROM dummy
WHERE 0 = 1;
ENDMETHOD. Herleitung der Request-TSN
Beschreibung
In BW on HANA gibt die AMDP-Schnittstelle die Request-Nummer nicht her. Sie muss etwas mühsam hergeleitet werden, um z.B. in einem Corporate Memory diese Nummer ablegen zu können (empfohlen, da man einzelne Requests zurückladen möchte und dieses Feld im Standard nicht als Selektion im DTP zur Verfügung steht).
Anmerkung
Beispiel AMDP-Feldroutine.
Es muss jeweils das Ziel-ADSO im Coding angegeben werden.
Coding Beispiel
METHOD PROCEDURE BY DATABASE PROCEDURE FOR HDB LANGUAGE SQLSCRIPT
OPTIONS READ-ONLY using RSPMREQUEST.
declare lv_reqtsn varchar(23);
SELECT request_tsn INTO lv_reqtsn FROM rspmrequest
where datatarget = '' AND
request_status = 'Y' AND
last_operation_type = 'C' AND
request_is_in_process = 'Y' AND
storage = 'AQ';
outtab =
SELECT lv_reqtsn AS "ETL_REQTSN",
record,
sql__procedure__source__record
FROM :inTab as input;
errortab =
SELECT '' AS "ERROR_TEXT" ,
'' AS "SQL__PROCEDURE__SOURCE__RECORD"
FROM dummy
WHERE 0 = 1;
ENDMETHOD. Aktuellste Daten eines wo-ADSOs
Beschreibung
Wenn Sie Daten aus einem schreiboptimierten ADSO lesen (wo-ADSO), geht es häufig dazu, den neuesten Stand dieser Daten zu lesen, also den neuesten Request. Dies geht ganz einfach durch Suche nach der maximalen Request-Nummer.
Coding Beispiel
SELECT T1.REQTSN, T1.KEY, T1.FIELD
FROM WO-ADSO as T1
JOIN ( SELECT MAX(REQTSN) as TSN, KEY FROM WO-ADSO GROUP BY KEY ) AS T2
ON T1.REQTSN = T2.TSN AND
T1.KEY = T2.KEY
WHERE T1.KEY = ...;
Nachlesen von Stammdaten
Beschreibung
Sie können Stammdaten eines InfoObjekts auslesen, indem Sie die P-Tabelle (bei zeitabhängigen Stammdaten die Q-Tabelle) des InfoObjekts hinzujoinen.
Anmerkung
Ist referentielle Integrität gegeben (d.h. existieren garantiert Stammdaten zu den Bewegungsdaten), dann kann ein INNER JOIN verwendet werden. Dieser ist performanter als ein OUTER JOIN.
Ansonsten verwendet man einen LEFT OUTER JOIN, und sollte das eventuell Auftreten von NULL-Werten durch COALESCE abfangen.
Coding Beispiel
SELECT T1.*,
COALESECE( T2.FIELD, '') AS FIELD
FROM ADSO as T1
LEFT OUTER JOIN /BIC/POBJECT AS T2
ON T2.KEY = T1.OBJECTFIELD
WHERE T2.OBJVERS = 'A' AND ...;
Im AMDP SQL-Fehler abfangen
Beschreibung
Treten im AMDP SQL-Fehler auf, so können diese abgefangen und als Fehlermeldungen an den DTP zurückgegeben werden.
Anmerkung
Das folgende Coding sollte dann an den Anfang des AMDP-Scripts gestellt werden.
Coding Beispiel
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
outtab = SELECT TOP 0 * from :outtab;
errortab = SELECT 'My Error Message' AS ERROR_TEXT,
'' AS SQL__PROCEDURE__SOURCE__RECORD FROM DUMMY';
END;
Im AMDP eigene SQL-Fehlermeldungen werfen
Beschreibung
Man kann auch eigene Fehlermeldungen werfen, die dann sowohl im Protokoll des DTPs als auch als SQL-Fehlermeldungen in den Tracefiles des Indexservers der HANA-DB auftauchen.
Anmerkung
Das folgende Coding sollte dann an den Anfang des AMDP-Scripts gestellt werden.
Coding Beispiel
DECLARE MYCOND CONDITION FOR SQL_ERROR_CODE 10001;
DECLARE EXIT HANDLER FOR MYCOND RESIGNAL;
SIGNAL MYCOND SET MESSAGE_TEXT = ' Typical Not-found Error';
-- in case of error throw here
SIGNAL MYCOND;
Im AMDP gültige Sätze verbuchen, fehlerhafte in Errorstack schreiben
Beschreibung
Ist man in einem BW/4HANA-Release, so muss man als Voraussetzung muss man in der Transformation die Einstellung „Fehlerhandling für HANA-Routinen erlauben“. Ist dies gesetzt, so definiert die AMDP-Schnittstelle neben der outTab-Tabelle auch eine errorTab-Tabelle.
Im DTP muss zusätzlich eine geeignete Einstellung vorgenommen sein, z.B. die Einstellung „Request auf grün setzen, Fehlerstack schreiben, gültige Sätze verbuchen“.
Anmerkung
Das folgende Coding zeigt beispielhaft, wie aus einer Stammdatentabelle Sätze nachgelesen werden. Diejenigen Sätze, bei denen ein nicht-leerer Eintrag gefunden wird, werden als gültige Sätze behandelt, die anderen werden als fehlerhafte Sätze behandelt.
Coding Beispiel
table1 = SELECT
:i_req_requid as ZTS1REQTSN,
CALYEAR,
COUNTRY,
PRODUCT,
I.RECORDMODE,
I."/BIC/ZTS1CNTRY",
COALESCE(P."/BIC/ZTS1FAREA",'') AS "/BIC/ZTS1FAREA",
to_nvarchar(current_utctimestamp, 'YYYYMMDDHH24MISS') AS UTC,
QUANTITY,
RECORD,
SQL__PROCEDURE__SOURCE__RECORD
FROM :inTab as I
LEFT OUTER JOIN "/BIC/PZTS1CNTRY" AS P
ON I."/BIC/ZTS1CNTRY" = P."/BIC/ZTS1CNTRY" AND
P.OBJVERS = 'A' AND
NOT ( P.RECORDMODE = 'R' );
-- Allow Error Handling for HANA Routines is enabled
if :i_error_handling = 'TRUE' then
errorTab = select
'FAREAMISSING' as ERROR_TEXT,
SQL__PROCEDURE__SOURCE__RECORD as SQL__PROCEDURE__SOURCE__RECORD
FROM :table1
where "/BIC/ZTS1FAREA" = '';
end if;
outTab = select * from :table1
where NOT ( "/BIC/ZTS1FAREA" = '' );