
SAP BW Apache Hadoop-Big Data-System
Das
Internet der Dinge, Big Data
und eine Fischertechnik-Fabrik
Jan Wiesemann
Architect
Die Herausforderung
Das Internet der Dinge (IoT) ist einer jener Begriffe, die sich inflationär in Nachrichten, Vorträgen und Veröffentlichungen finden und deren häufige Verwendung zum schnellen Überdruss beim geneigten Leser führen. Die natürliche Reaktion auf das Auftreten solcher Modebegriffe ist das Abwarten, ob die Welle nicht genauso schnell abklingt wie sie aufgekommen ist. Wiewohl einzelne Begriffe und Schlagwörter wieder zu Recht im Orkus des Vergessens verschwinden werden, so ist doch mit an Sicherheit grenzender Wahrscheinlichkeit davon auszugehen, dass die hinter den Begriffen stehende Problematik bestehen bleibt, ja sogar immens an Grösse und Bedeutung gewinnen wird:
1. Die Datenmengen werden immer grösser.
Zu dieser Behauptung werden jedem Einzelnen sicherlich genügend Beispiele der letzten Zeit einfallen. Ob es nun selbstfahrende Autos sind, die einen Strom an Daten aussenden und empfangen, ob es die Supermarkt-Sparkarten sind, die unser Konsumverhalten nicht nur verbilligen, sondern auch registrieren, ob es neue Apps auf den Smartphones oder Smartwatches sind, die uns nicht nur unterstützen, sondern auch kategorisieren, die Liste an Beispielen ist nicht nur bereits lang, sie scheint auch mit immer höherer Geschwindigkeit an Länge zu gewinnen.
Gelegentlich fällt einem diese Entwicklung an einzelnen Beispielen besonders auf. So stach mir ein Bericht auf SPIEGEL ONLINE vom 15.11.2017 ins Auge, in dem von einer Pille berichtet wurde, die ihre Einnahme meldet und die Daten in die Cloud sendet: Sinn und Zweck dieser Pille mit Daten ist die Überwachung der regelmässigen Einnahme von Medikamenten. Sofort stellen sich weitere Fragen: meldet die Pille auch, wenn sie z.B. innerhalb einer Stunde den Körper wieder verlassen hat (das lässt auf Erbrechen schliessen, damit zählt die Pille als nicht eingenommen)? Meldet sie weitere Zwischenstationen auf dem Weg durch den Körper? Dieses Beispiel zeigt sehr deutlich, wie wir als Personen zur Quelle eines Datenstroms werden, der in seinen Ausmassen ins Ungeheure anwachsen kann.
2. Die Datenqualität ist eher mässig gut.
In der Masse von Daten und Meldungen sind Fehler mit grösserer Häufigkeit vertreten. Es kommt nun mal zu temporären Falschmeldungen (Sensor defekt, die Smartwatch kann aufgrund von körperlicher Bewegung mal für eine Zeit die Herzfrequenz nicht ermitteln, usw.) und aufgrund der Masse an Daten ist es nicht möglich, sich die Zeit zu nehmen, alle falschen Daten zu finden und zu eliminieren. Sind falsche Daten systematisch erkennbar, so können sie sicherlich ausgefiltert werden und bei grösserer Zahl lohnt es sich dann auch zu versuchen, die Ursache zu beseitigen. Aber allein aufgrund der grossen Zahl an Datenlieferanten muss man einen Bodensatz an falschen Werten akzeptieren und in Kauf nehmen.
Aus der Sicht eines Enterprise Data Warehouse ergeben sich damit neue Herausforderungen:
- Neue Datenquellen können plötzlich und in grosser Zahl hinzukommen. Die Verknüpfung dieser Daten ermöglich ganz neue Auswertungen und Erkenntnisse. Es ist aber ein hohes Mass an Flexibilität und Agilität nötig, um diese Datenräume verfügbar zu machen.
- Die Datenmengen sind potenziell riesig. Es ist gut möglich, dass sich das Datenaufkommen z.B. um einen Faktor 1000 vergrössert. Wenn daraufhin sich die Berichtsanzahl um den Faktor 1000 vergrössert oder einzelne Berichte nun 1000 Mal länger sind, wird sich die Begeisterung der Anwender in Grenzen halten. Der Mehrwert des Data Warehouses besteht ja gerade darin, durch eine Verdichtung erst einen Blick für das Ganze zu bekommen und nur für gewisse Einzelanalysen den Abstieg bis auf den einzelnen Datensatz zu ermöglichen.
- Die Verknüpfung mit qualitativ hochwertigen Stammdaten bringt den Mehrwert. Die Masse an Bewegungsdaten bietet die Gefahr, dass ihre Auswertung in Beliebigkeiten endet. Man sieht, was man sehen will oder was sich eher zufällig ergibt. Hat man beispielweise die Verkaufsumsätze einzelner Ladengeschäfte, so ist aus den Verkaufsumsätzen allein schlecht abzulesen, warum sich ein Artikel mal gut und mal schlecht verkauft. Nimmt man aber die Stammdaten der Läden hinzu, wie z.B. Grösse des Ladens, Öffnungszeiten, Lage des Ladens, so sind die Ergebnisse deutlich belastbarer.
Konsequenzen für die Architektur
Im ersten Teil dieses Blogs habe ich die Herausforderungen benannt, die Big Data für ein Data Warehouse darstellt.Für die Big Data-Architektur eines solchen EDW im konkreten Fall eines SAP BW on HANA oder SAP BW/4HANA ergeben sich damit bereits einfache Schlussfolgerungen:
- Es ist nicht möglich, alle Daten in die SAP HANA zu laden. Die Datenmengen sind einfach zu gross, die HANA-Hardware für diesen Fall unverhältnismässig teuer. Es empfiehlt sich für die Masse an Rohdaten eine entsprechend skalierbare und kostengünstige Lösung zu verwenden, z.B. ein Apache Hadoop-Cluster. Solche Cluster bieten Skalierbarkeit über eine grosse Masse an günstiger Hardware und rechnen bereits in ihrer Architektur mit dem ständigen Ausfall einzelner Teile. So speichert das Hadoop-Filesystem HDFS die Daten immer mehrfach und ist daher betriebsbereit selbst wenn einzelne Server ausfallen. Gleichzeitig muss das System natürlich berücksichtigen, dass es die Mehrfach gespeicherten Daten nicht mehrfach zählt oder liefert. Dazu ist Hadoop entworfen worden. Von diesen grossen Datenmengen auf der Hadoop-Seite können nun kleinere Extrakte oder Aggregate durchaus in die HANA geladen werden, oder schon auf der Hadoop-Seite in-Memory vorgehalten werden, z.B. mit Hilfe des Spark-Adapters, wie sie auch in SAP Vora verwendet werden.
- Nicht nur Daten, sondern auch Ereignisse müssen orchestriert werden. Das Auftreten bestimmter Ereignisse in den Daten (z.B. Alarmmeldungen) kann sowohl auf der Big Data-Seite, dem Hadoop-Cluster, als auch auf der BW-Seite gewisse Prozesse triggern (Nachladen von Daten, Erstellen von Servicemeldungen, usw.). Diese Ereignisse müssen auf beiden Seiten jeweils orchestriert werden, damit Prozesse technologieübergreifend definiert werden können. Der SAP Data Hub bietet neben der Verwaltung der Datentransfers eben solch auch eine gemeinsame Verwaltung von Ereignissen, Jobs oder Triggern an.
All diese Überlegungen sind doch immer wieder recht abstrakt. CubeServ hat daher eine Fabriksimulation der Firma Fischertechnik erworben, um einmal ganz konkret eine solche Architektur aufzubauen und zu demonstrieren. Die Fabrik besteht aus einem Hochregallager, aus einem zentralen Kran, aus einem Brennofen und einer Sortieranlage. Die Güter der Fabrik sind weisse, rote und blaue Plastikzylinder, die im Hochregal jeweils noch in rechteckigen schwarzen Boxen liegen.
Die Fabrik in Aktion
Ein farbiges Gut wird aus der Sortierrutsche für Weiss genommen (wo es fälschlicherweise liegt), vom Kran zum Brennofen gebracht, von dort zum Sortierband und dort dann in die richtige Rutsche einsortiert.
Die einzelnen Bereiche werden separat gesteuert, aber ein kompletter Kreislauf kann so aussehen: ein Gut wird aus dem Hochregal entnommen, der zentrale Kran bringt es zum Brennofen, dort wird es (symbolisch durch blitzende Lichter) bearbeitet. Aus dem Brennofen kommt es zur Sortieranlage, eine Fotozelle erkennt die Farbe und entsprechend wird es in eines von drei Rutschen einsortiert. Von dort wird es wieder vom Kran entnommen und zum Hochregal gebracht, wo es wieder einsortiert wird. Die einzelnen Bereiche verfügen zum Teil über Sensoren wie Lichtschranken oder Fotozelle zur Farberkennung und über Motoren.

Die Fabrik wird bereits komplett montiert geliefert, allerdings ohne Steuergeräte und demzufolge auch ohne entsprechende Programmierung. Um die Fabrik zu steuern, wurden acht Siemens Logo 8 Steuergeräte an die entsprechenden Sensoren und Motoren angeschlossen. Die Steuerung in der Logo-Sprache wurde dann von unserem Basis-Experten, Peter Straub, vorgenommen. Diese Programmierung ist recht aufwändig, die zur Verfügung gestellten Bestandteile von Sprache und Fabrik sind sehr einfach gehalten. Es gibt wenige Sensoren. Soll z.B. der zentrale Kran in Grundstellung gedreht werden, so wird er einfach eine bestimmte Zeit in eine bestimmte Richtung gedreht. Da er nicht über einen festmontierten Anschlag hinausdrehen kann, ist er damit in 0-Stellung. Die Bestandteile der LOGO-Sprache sind ebenfalls sehr elementar (UND-Gatter, ODER-Gatter, Zeitverzögerung und ähnliches). Es gibt z.B. keine komfortablen Variablen, die man z.B. für die Lagerhaltung nutzen könnte. Für die Verdrahtung der Geräte und der Programmierung der Fabrik kamen dann doch in etwa vier Wochen Aufwand zusammen.
Der Big Data-Cluster
In den ersten beiden Teilen dieses Blogs haben wir die Fischertechnik Fabriksimulation gezeigt. Diese Fabriksimulation soll nun kontinuierlich Daten erzeugen, die einerseits in einem Big Data-Cluster landen sollen, andererseits mit Mitteln des SAP BW oder mit SAP Analytics for Cloud reportbar sein sollen.
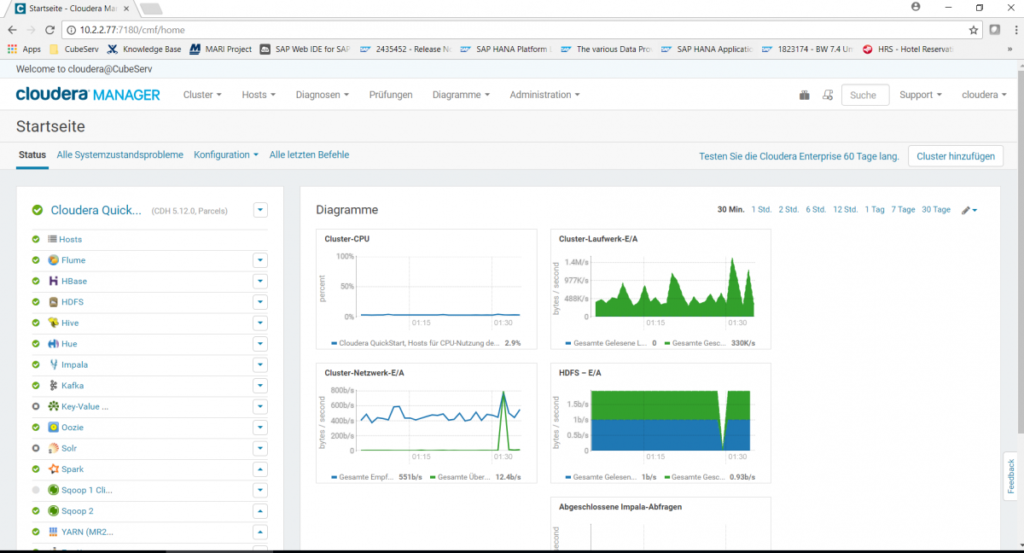
Als Big Data-Cluster wurde bei uns eine Cloudera-Installation aufgebaut. Ähnlich wie bei Linux, dem kostenlosen open-Source-Betriebssystem, das man in vorkonfigurierten und dann kostenpflichtigen Versionen erwerben kann (z.B. Suse Linux, RedHat,…), gibt es von Apache Hadoop ebenfalls vorkonfigurierte Installation wie z.B. von Hortonworks oder von Cloudera. Wir haben uns für Cloudera entschieden und haben eine 60-Tage-kostenlose Enterprise Edition installiert. Da es sich nur um eine Demoanwendung handelt, ist es auch ein einfacher Cluster mit nur einem Knoten geworden.
Hadoop kommt mit einer ganzen Reihe von Services daher, die dem Laien erstmal wenig sagen und in ihrer Anzahl und Bedeutung zunächst sehr verwirrend sind.
- HBase ist die Datenbank des Systems.
- HDFS ist das Hadoop Distributed File System, welches Daten redundant speichert und damit hohe Ausfallsicherheit garantiert.
- Hive ist ein Service, der SQL-artige Abfragen gegen die Datenbank des Systems erlaubt.
- Impala ermöglicht schnellere SQL-Abfragen als Hive durch bessere parallele Algorithmen. Impala dient vor allem dem schnellen Lesen und weniger anderen Vorgängen, wie Anlegen, Schreiben oder Ändern.
- Hue ist ein Service, der eine SQL-Abfrage-Workbench und –Visualisierung bietet. Hier kann man z.B. SELECT-Statements ausprobieren (und dabei wählen, ob man über die Hive- oder die Impala-Engine abfragen möchte).
- Kafka ermöglicht das Laden und Exportieren von Datenströmen.
- Oozie ist der Service, mit dem Batch-Jobs eingeplant werden.
- YARN ist die Ressourcen-Verwaltung, die auch die Zuteilung von Abfragen zu Servern steuert.
- Flume ist ein Service, um Logs nach Hadoop zu streamen.
Hadoop kommt mit einer ganzen Reihe von Services daher, die dem Laien erstmal wenig sagen und in ihrer Anzahl und Bedeutung zunächst sehr verwirrend sind.
- HBase ist die Datenbank des Systems.
- HDFS ist das Hadoop Distributed File System, welches Daten redundant speichert und damit hohe Ausfallsicherheit garantiert.
- Hive ist ein Service, der SQL-artige Abfragen gegen die Datenbank des Systems erlaubt.
- Impala ermöglicht schnellere SQL-Abfragen als Hive durch bessere parallele Algorithmen. Impala dient vor allem dem schnellen Lesen und weniger anderen Vorgängen, wie Anlegen, Schreiben oder Ändern.
- Hue ist ein Service, der eine SQL-Abfrage-Workbench und –Visualisierung bietet. Hier kann man z.B. SELECT-Statements ausprobieren (und dabei wählen, ob man über die Hive- oder die Impala-Engine abfragen möchte).
- Kafka ermöglicht das Laden und Exportieren von Datenströmen.
- Oozie ist der Service, mit dem Batch-Jobs eingeplant werden.
- YARN ist die Ressourcen-Verwaltung, die auch die Zuteilung von Abfragen zu Servern steuert.
- Flume ist ein Service, um Logs nach Hadoop zu streamen.
Die Fischertechnik Fabrik wird ja über die Siemens Logo Steuergeräte gesteuert. Die Steuergeräte bzw. ihre Programmieroberfläche bietet nun die Möglichkeit, die Zustände aller vorhandenen Eingänge und Ausgänge in periodischen Abständen (z.B. 1s) in ein Protokollfile wie z.B. Log.csv zu schreiben.
Es werden immer alle Ein- und Ausgänge geschrieben, wir haben uns zunächst aber nur auf drei beschränkt, und zwar die Steuerungen für die Sortier-Rutschen, die weisse, rote und blaue Plastikzylinder voneinander trennen, abhängig von der erkannten Farbe in der Photozelle.
Damit wurde ein möglichst einfacher Bericht aufgebaut, nämlich ein einfacher Zähler, der gezählt hat, wie oft eine 1 vom Motor Q2 (weiss), Q3 (rot) oder Q4 (blau) gemeldet wurde. Dies entsprach dann der entsprechenden Anzahl an durchgelaufenen Plastikgütern.

Die Siemens-Steueroberfläche schreibt also permanent in ein lokales CSV-File auf dem Laptop, mit dem die kleine Anlage gesteuert wird. Dies ist also die Quelle unserer Sensordaten. Auf dem Cloudera-System wurde nun per Samba das Directory, in dem dieses Protokollfile geschrieben wird, gemountet. Damit war aus Sicht des Cloudera-Systems lokal ein CSV-File vorhanden. Gleichzeitig bestand keine Gefahr, dass eine kurzzeitige Unterbrechung der Verbindung zum Abbruch des Schreibvorgangs führt. Das Schreiben lief permanent weiter und sollte die Verbindung via Internet einmal unterbrochen sein, so würden die neuen Daten mit der nächsten Wiederverbindung wieder abholbar sein.
Dieses lokal sichtbare CSV-File, das LogFile.csv, wird nun mit Hilfe eines Flume-Agenten permanent auf ein Ziel in Kafka geschrieben. Die entsprechende Konfigurationsanweisung, die eine Quelle, ein Ziel (Senke) und einen Kanal definiert, lautet wie folgt:
#————————————
tier1.sources = r1
tier1.sinks = k1
tier1.channels = c1
# Describe/configure the source
tier1.sources.r1.type = TAILDIR
tier1.sources.r1.filegroups = f1
tier1.sources.r1.filegroups.f1 = /samba/FischerTechnik/LOG/LogFile.csv
tier1.sources.r1.positionFile = /tmp/flume-position_3.json
# Describe the sink
tier1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
tier1.sinks.k1.topic = sensor_csv
tier1.sinks.k1.brokerList = quickstart.cloudera:9092
tier1.sinks.k1.batchSize = 1
# Use a channel which buffers events in memory
tier1.channels.c1.type = memory
tier1.channels.c1.capacity = 100000
tier1.channels.c1.transactionCapacity = 10000
# Bind the source and sink to the channel
tier1.sources.r1.channels = c1
tier1.sinks.k1.channel = c1
#————————————
Für die Einrichtung dieser Konfiguration nochmal herzlichen Dank an die Experten unserer Partnerfirma für Hadoop-Systeme, die Ultra Tendency GmbH (www.ultratendency.com), und hier speziell an Matthias Baumann, der uns mit seiner Hadoop-Expertise schon einige Mal weitergeholfen hat.
Damit liegt nun im Cloudera im HDFS-Filesystem die Datei sensor_csv vor, die im Sekundentakt neue Daten erhält. Um dieses CSV-File für SQL-Abfragen verfügbar zu machen, wird in Hive folgendes Kommando abgesetzt:
CREATE EXTERNAL TABLE sapt90.zcssensorq (
key varchar(6),
time VARCHAR(8),
value VARCHAR(4),
sensor VARCHAR(20)
)
STORED BY “org.apache.hadoop.hive.hbase.HBaseStorageHandler”
WITH SERDEPROPERTIES (
“hbase.columns.mapping” =
“:key,default:time,default:value,default:sensor”
)
TBLPROPERTIES(“hbase.table.name” = “sensor_csv”)
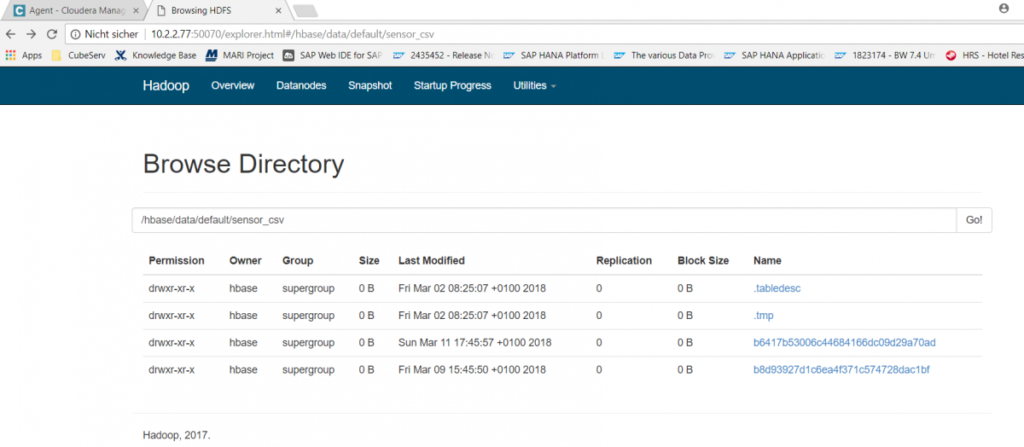
Dieses Kommando erzeugt eine leere Tabellenhülle zcssensorq (in einem Schema mit dem Namen sapt90) mit 4 Spalten (key, time, value, sensor) und teilt dem System mit, dass der Inhalt dieser Tabelle sich in einer hbase-Tabelle mit dem Namen sensor_csv befindet. Auf diese Weise können nun im Hue-Service einfache Hive- oder Impala-Abfragen gestartet werden, z.B. select * from zcssensorq;:
Die Sensordaten der Fischertechnik-Fabrik werden damit kontinuierlich geschrieben und liegen als File bzw. als Tabelle im Hadoop System verfügbar vor. Wie können diese Daten nun für ein Reporting verfügbar gemacht werden? Darum geht es im nächsten Teil dieses Blogs.

Zugriff von einer SAP HANA aus via Smart Data Integration (SDI)
In den beiden vorherigen Teilen dieses Blogs habe ich beschrieben, wie die Fischertechnik-Fabriksimulation Daten in Form eines CSV-Files erzeugt und wie diese Daten in das Hadoop Cluster gelangen und dort sogar als Tabelle zur Verfügung stehen. In diesem Teil geht es nun um die verschiedenen Möglichkeiten, wie nun über den Inhalt dieser Tabelle berichtet werden kann. Es gibt zwei relativ einfache Möglichkeiten, wie die Daten dieser Hadoop-Tabelle für SAP Tools zur Verfügung gestellt werden können:
1. In einer HANA-Datenbank via SDA (Smart Data Access) bzw. SDI (Smart Data Integration). Die Daten können dann z.B. in einer SAP Analytics for Cloud konsumiert werden (hierzu ist dann kein SAP BW-System nötig) oder in einem SAP BW-System konsumiert werden.
2. Mit Hilfe der Middleware GLUE unserer Partnerfirma Datavard ist es sehr einfach, mit ABAP-Transaktionen Tabellen in Hadoop zu erzeugen, sie auszulesen oder Inhalte zwischen in Hadoop liegenden Tabellen und ABAP-Tabellen hin- oder herzuschieben. Dazu ist nicht zwingend eine HANA-Datenbank nötig, aber ein ABAP-Application Server. Ich möchte beide Möglichkeiten hier vorstellen.
SDA / SDI
SDA / SDI SDA bzw. SDI sind von der SAP ausgelieferte Konnektor-Bibliotheken. Sie ermöglichen, eine remote-Datenbank anzuschliessen und zu den Tabellen dieser remote Datenbank virtuelle Links zu generieren. Auf diese virtuellen Links kann dann zugegriffen werden, als würde es sich um lokale Tabellen in der HANA Datenbank handeln. Die SDI-Adapter sind dabei technologisch weiter fortentwickelt und verfügen über zusätzliche Fähigkeiten im Vergleich zu den SDA-Adaptern. Z.T. sind sie z.B. fähig, nur die Delta-Änderungen zu extrahieren, indem sie nicht die Tabellen, sondern die Changelogs auswerten. Ob und über welche Fähigkeiten die Adapter verfügen, muss man im Einzelfalle prüfen, z.B. im Hadoop-Fall verfügen die Adapter über diese Delta-Fähigkeit nicht. Des Weiteren sind die SDI-Adapter im Gegensatz zu SDA zusätzlich kostenpflichtig.
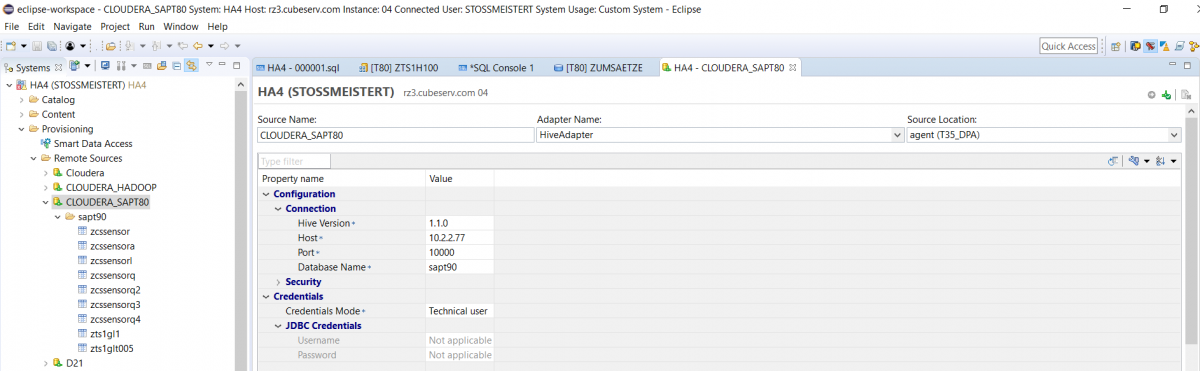
Wir haben unsere HANA-Datenbank (HA4) zu Testzwecken sogar mit zwei verschiedenen SDI-Adapter angeschlossen, einmal über den SDI-HiveAdapter und einmal über den SDI-ImpalaAdapter.
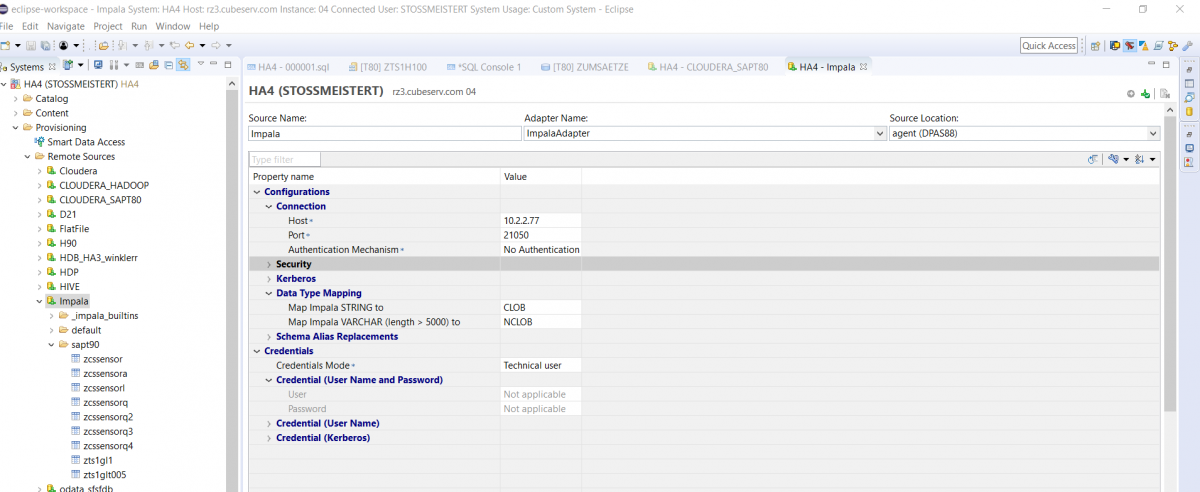
Damit ist kann man nun leicht virtuelle Tabellenlinks (hier im Schema DATA_EXTERN) anlegen, mit deren Hilfe auf die Originaltabelle zugegriffen werden kann.
Dies funktioniert auch ganz wunderbar, wie z.B. folgende Abfrage zeigt:

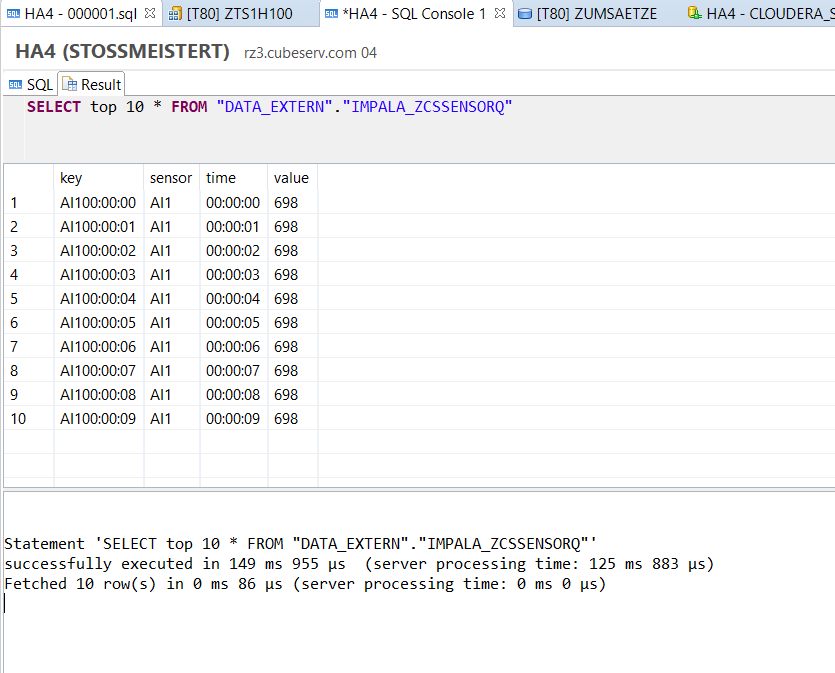
Visualisierung mittels CalculationView und SAP Analytics Cloud
In den vorherigen Teilen dieses Blogs wurde gezeigt, wie die Sensordaten der Fabriksimulation schliesslich als Tabelle (genauer: als Tabellenlink) in der SAP HANA verfügbar gemacht wurde. Der nächste Schritt wäre nun beispielsweise in der HANA einen gescripteten (oder alternativ auch graphischen) CalculationView anzulegen, der die Meldungen der Motoren Q2, Q3 und Q4 in etwa wie folgt liest (am Beispiel Q2):
SELECT count(*) FROM “DATA_EXTERN”.”IMPALA_ZCSSENSORQ” where “sensor” = ‘Q2’ and “value” = ‘1’;
Leider sind wir dabei aber gegen einen Bug im SAP-Adapter gelaufen, der Adapter produziert eine fehlerhafte Abfrage mit unsinnigen „N“-Literalen in der Query:
Could not execute ‘SELECT count(*) FROM “DATA_EXTERN”.”IMPALA_ZCSSENSORQ” where “sensor” = ‘Q2’ and “value” = ‘1” in 89 ms 673 µs . SAP DBTech JDBC: [403]: internal error: Error opening the cursor for the remote database Failed to execute query [SELECT COUNT(*) FROM `sapt90`.`zcssensorq` `IMPALA_ZCSSENSORQ` WHERE (`IMPALA_ZCSSENSORQ`.`sensor` = N’Q2′) AND (`IMPALA_ZCSSENSORQ`.`value` = N’1’)]. for query “SELECT COUNT(*) FROM “””sapt90″”.””zcssensorq””” “IMPALA_ZCSSENSORQ” WHERE “IMPALA_ZCSSENSORQ”.”sensor” = ‘Q2’ AND “IMPALA_ZCSSENSORQ”.”value” = ‘1’ “
Dieser Fehler im Impala-Adapter wird bereits im SAP-Hinweis „2562391 – Keine SQL-Abfrage gegen eine virtuelle Impala-Tabelle mit Literalzeichenfolge in der WHERE-Bedingung“ beschrieben. Die Lösung besteht leider in keinem einfachen Patch, sondern der benutze SDI-Agent vom Release 1.0 muss durch eine 2.0-Installation ersetzt werden. Da vorhandene Verbindungen, die diesen Agenten benutzen, dabei verloren gehen und neu angelegt werden müssen, wurde die Installation eines neuen 2.0-Agenten separat vorangetrieben, die Modellierung aber mit dem fehlerhaften 1.0-Agenten fortgesetzt, um doch möglichst schnell einen funktionierenden Prototypen zu erhalten. Da nun gegen die Impala-Adapter keine WHERE-Bedingungen gefeuert werden dürfen und doch Impala wegen der besseren Geschwindigkeit im Vergleich zu Hive verwendet werden sollte, wurde folgendes gemacht:
1. Bereits auf der Hadoop-Seite wurde neben der Tabelle zcssensorq auch die Tabellen zcssensorq2, zcssensorq3 und zcssensorq4 gefüllt, und zwar nur für die Tabellenzeilen, bei denen der Sensorwert = 1 war. Die Tabellen enthalten also nur die Aktiv-Meldungen des entsprechenden Q-Sensors und sonst nichts. Damit müssen nur die Zeilen der Tabelle gezählt werden ohne jede WHERE-Bedingung.
2. Es wurde in der HANA ein CalculationView angelegt, der folgendes Zählen durchführt:
tmp1 = select count( * ) as “COUNT_Q2” from “DATA_EXTERN”.”IMPALA_ZCSSENSORQ2″;
tmp2 = select count( * ) as “COUNT_Q3” from “DATA_EXTERN”.”IMPALA_ZCSSENSORQ3″;
tmp3 = select count( * ) as “COUNT_Q4” from “DATA_EXTERN”.”IMPALA_ZCSSENSORQ4″;
var_out = select “COUNT_Q2”, “COUNT_Q3”, “COUNT_Q4” from :tmp1, :tmp2, :tmp3;
Leider führt aber selbst dieses WHERE-freie Coding zu einem Abfragefehler aufgrund des Bugs im Impalaadapter. Grund ist, dass die HANA diese Abfrage optimiert und dabei dich wieder WHERE-Bedingungen entstehen. Als Workaround wurde das System gezwungen, diese Optimierung sein zu lassen und die Abarbeitung wirklich sequentiell vorzunehmen. Dies gelang durch die folgenden Befehle, die die entscheidenden Worte „SEQUENTIAL EXECUTION“ enthalten:
drop procedure “_SYS_BIC”.”pg.ccedw.sfb18/ZTS1_CV_SFB_COUNTER_Q24/proc”;
create procedure “_SYS_BIC”.”pg.ccedw.sfb18/ZTS1_CV_SFB_COUNTER_Q24/proc” ( OUT var_out
_SYS_BIC”.”pg.ccedw.sfb18/ZTS1_CV_SFB_COUNTER_Q24/proc/tabletype/VAR_OUT” ) language sqlscript sql security definer reads sql data
as
/********* Begin Procedure Script ************/
BEGIN SEQUENTIAL EXECUTION
tmp1 = select count( * ) as “COUNT_Q2” from “DATA_EXTERN”.”IMPALA_ZCSSENSORQ2″;
tmp2 = select count( * ) as “COUNT_Q3” from “DATA_EXTERN”.”IMPALA_ZCSSENSORQ3″;
tmp3 = select count( * ) as “COUNT_Q4” from “DATA_EXTERN”.”IMPALA_ZCSSENSORQ4″;
var_out = select “COUNT_Q2”, “COUNT_Q3”, “COUNT_Q4” from :tmp1, :tmp2, :tmp3;
END /********* End Procedure Script ************/
Dieser Trick ist natürlich nur ein temporärer Workaround und z.B. nicht stabil gegen die erneute Aktivierung des CalculationViews. Als Notlösung zählt aber nun dieser gescriptete CalculationView wie gewünscht die Tabelleneinträge:
Die Dauer zwischen Auslösen des entsprechenden Motors und dem Hochzählen des Zählers beträgt dabei ca. 4 Sekunden. Dieser View wurde nun in SAP Analytics for Cloud eingebunden. Leider gibt es dort keine Darstellung, die sich selbständig periodisch aktualisiert, daher muss man leider aktuell immer wieder die Darstellung auffrischen, um die Veränderung der Zähler zu sehen.
Insgesamt sieht die Architektur also folgendermassen aus: Sensordaten werden von den Steuergeräten in ein CSV-File geschrieben, dieses wird via Kafka in Cloudera importiert, über Adapter der HANA-Datenbank sind diese in einer HANA verfügbar und SAP Analytics for Cloud bringt diese Daten zur Anzeige. In dieser Architektur ist kein SAP BW beteiligt. Im nächsten Teil dieses Blogs werde ich noch darauf eingehen, wie es möglich ist, solche Daten zwischen Hadoop und SAP BW einfach hin- und herzuschieben.


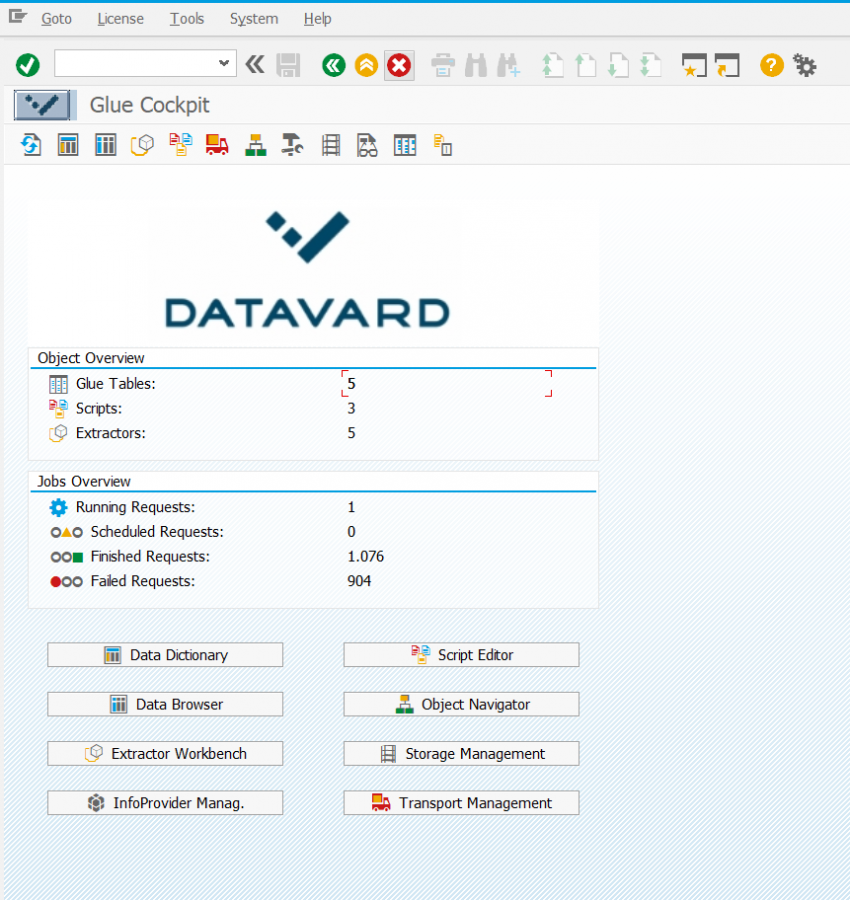
Hadoop vom ABAP aus ansprechen: die GLUE-Middleware von Datavard
Im vorherigen Teil wurden Daten von Steuergeräten in ein CSV-File geschrieben, dies wurde per Kafka in Hadoop importiert und via Hive-Adapter bzw. Impala-Adpater in einer HANA-Datenbank gelesen. Diese Adapter stellen eine komfortable Möglichkeit dar, um auf die Hadoop-Daten lesend zuzugreifen. Diese Adapter ermöglichen allerdings nicht einen schreibenden Zugriff auf die Tabellen. Will man z.B. Daten, die nicht mehr besonders wichtig sind, aber dennoch nicht gelöscht werden sollen („cold data“) in das Hadoop verschieben, so geht das nicht über diese Adapter.
Eine einfache Möglichkeit, Daten zwischen einem ABAP-System und Hadoop hin- oder herzuverschieben, bietet die Middleware GLUE, die von unserer Partnerfirma Datavard entwickelt und vertrieben wird. Sie bietet die Möglichkeit, vom ABAP aus Tabellen in Hadoop zu definieren (diese heissen dann GLUE-Tabellen) und zwar so ähnlich wie man das in der SE11 macht. Der Inhalt dieser Tabellen lässt sich so einfach wie mit der SE16 anzeigen, und auch das Schreiben in diese Tabellen ist sehr einfach. Die GLUE-Software setzt einen Applikationsserver auf Linux voraus, es ist aber keine HANA-Datenbank zwingend vorausgesetzt, die Software funktioniert auch auf klassischen Datenbanken.
Ein Beispiel: nach erfolgreichem Import per ABAP-Transportaufträge und nach entsprechender Konfiguration, steht die Transaktion /DVD/GLUE als zentraler Einstiegspunkt zur Verfügung.
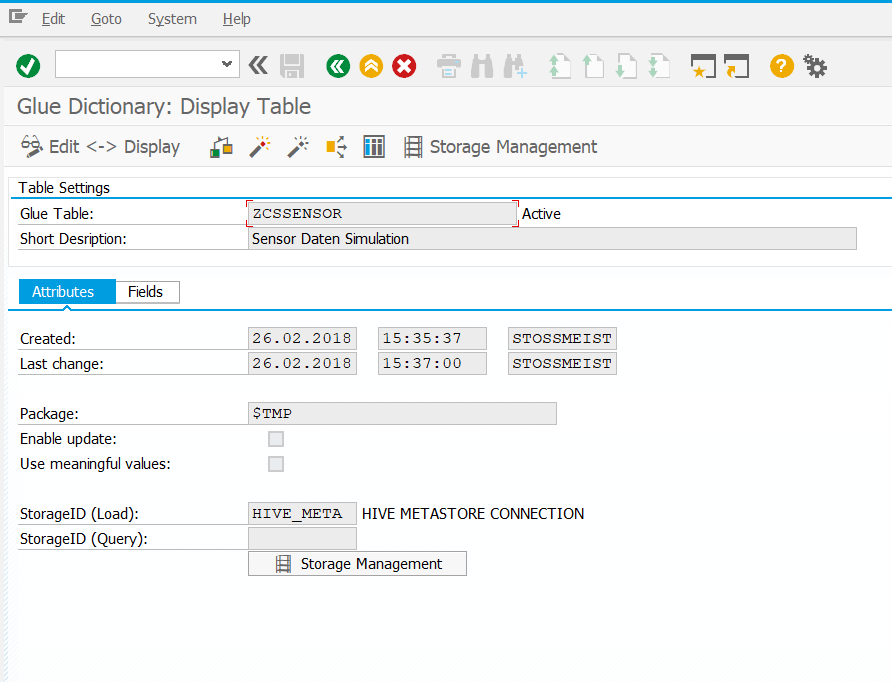
Im Data Dictionara lässt sich z.B. eine Tabelle ZCSSENSOR definieren.
Nach Aktivierung findet sich diese Tabelle dann im Hadoop wieder.
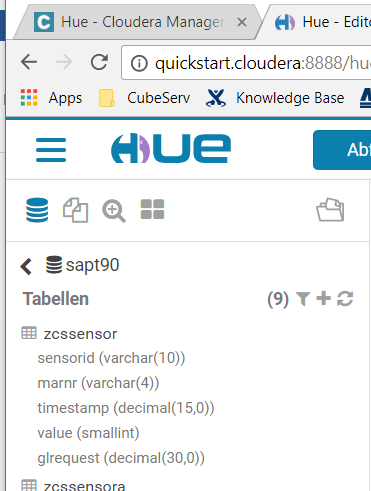
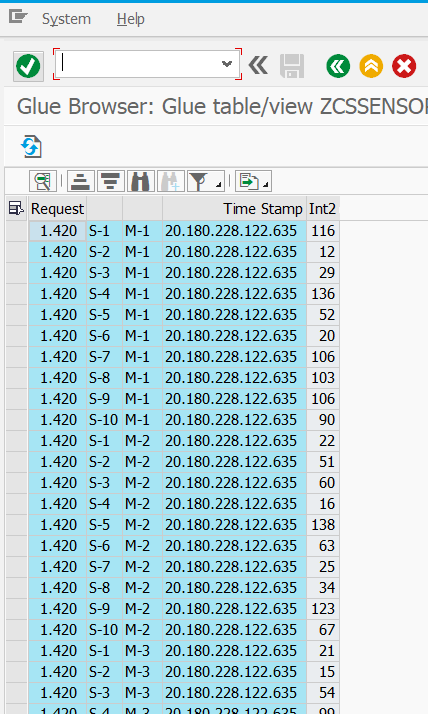
Ebenso einfach kann der Inhalt dieser Tabelle im ABAP zur Anzeige gebracht werden.
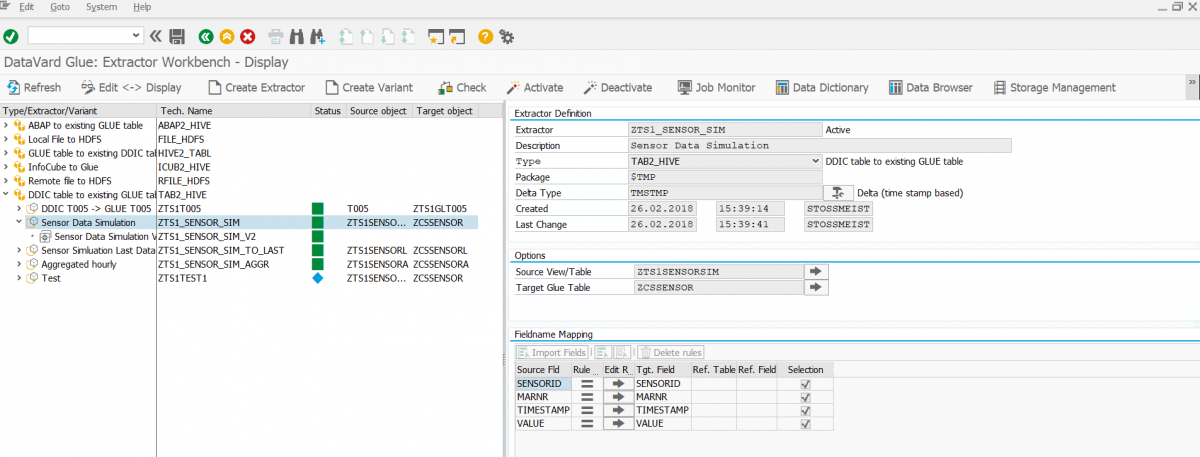
Wie wurden nun diese Daten, die man hier sieht, in diese Tabelle gebracht? In /DVD/GLUE findet sich die Extraktor-Workbench. Hier kann man eine Art Transformation z.B. zwischen einer ABAP-Tabelle aus dem DDIC und einer GLUE-Tabelle definieren.
Zusätzlich zu diesem Extraktor (er entspricht in etwa einer Transformation) wird eine Variante definiert (sie entspricht in etwa einem DTP). Diese Variante kann dann als Job eingeplant werden und führt dann den Datentransfer durch. Nach der Durchführung kann man im entsprechenden Job-Log sehen, wie der Transfer durchgeführt wurde (hier am Beispiel der Tabelle zcssensorl).
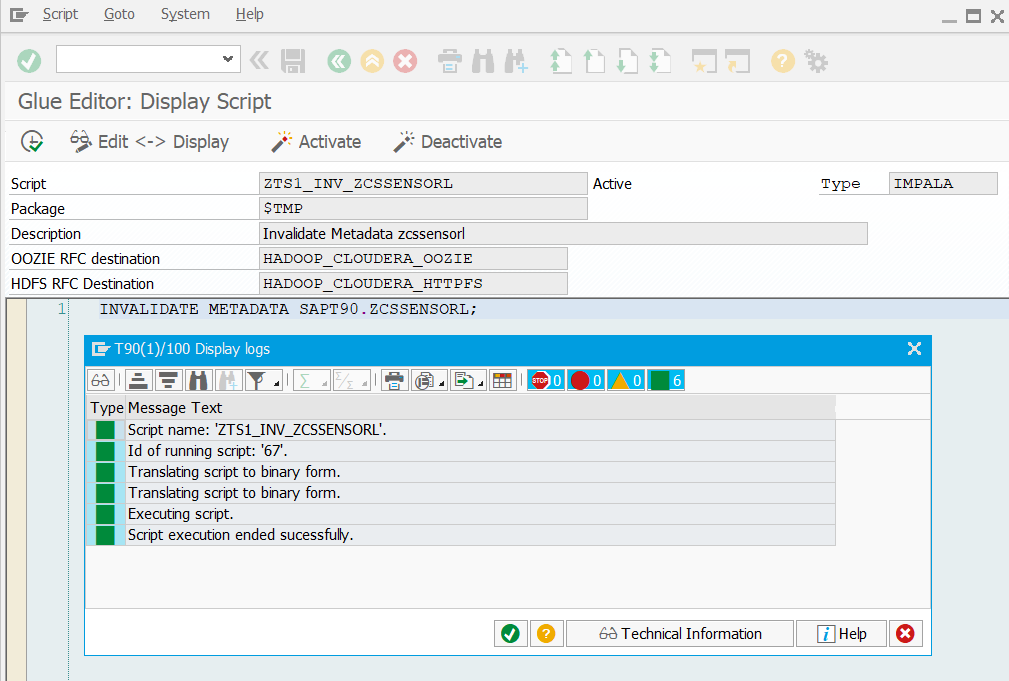
Wie früher im Blog bereits erwähnt, benötigt man im Allgemeinen nicht nur einen Austausch von Daten, sondern auch eine Orchestrierung von Ereignissen. GLUE bietet dabei die Steuerung zentral aus dem ABAP heraus an. Mit Hilfe des Script Editors können im ABAP Befehle an das Hadoop definiert werden.
Und diese Befehle dann auch aus dem ABAP heraus gestartet werden:



Insgesamt bietet GLUE einen komfortablen Weg, aus dem ABAP heraus Hadoop anzusprechen und zu benutzen. Dem Anwender eröffnet sich damit die Hadoop-Welt, ohne dass er sich tief in die Einzelheiten dieser Technik einarbeiten muss.
Unser Angebot